원문 : https://arxiv.org/abs/1909.08053
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Recent work in language modeling demonstrates that training large transformer models advances the state of the art in Natural Language Processing applications. However, very large models can be quite difficult to train due to memory constraints. In this wo
arxiv.org
개요
이번 포스팅에서는 Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism 논문을 공부합니다.
나는 사용했다. 번역을 위해서 구글 번역기
Reference
들어가기 전
FLOPS(FLoating point Operations Per Second)
- 컴퓨터 성능을 수치로 나타내는 단위
PetaFlops
- 1초당 1000조 번의 수학 연산처리를 뜻함, TeraFlops의 1000배에 달하는 능력
Gradient clipping
memory footprint
activation checkpointing
%warning%
Meagatron-LM에서 보여주는 방법이 기술적인 부분에서 너무 깊다고 판단하여,
모든 내용을 이해하지는 않고 "이런 걸 했네" 정도로만 이해하고 포스팅하였습니다.
Abstract
언어 모델링에 관한 최신 연구를 보면
- Transformer 모델의 크기를 크게 할수록 좋은 성능을 내는 것을 알 수 있음
하지만
- 엄청 큰 모델은 학습하는데 메모리 제약이 있음
이번 연구에서
- 매우 큰 transformer 모델을 학습하기 위한 기술(techniques)을 제시함
또한
- 엄청 큰 transformer 모델을 훈련할 수 있는 간단 & 효율적인 텐서(intralayer) 모델 병렬 처리를 구현함
이 방법은 컴파일러나 라이브러리를 바꿀 필요 없이
- 모델 병렬 처리(model parallelism)를 할 수 있음. pytorch 사용해서 구현 가능함
모델이 커질수록 성능과 기술의 발전이 비례하다는 것을 입증하기 위해
- GPT-2와 유사한 83억 개의 매개변수(parameter)를 가진 transforemr LM과 BERT와 유사하게 39억 개의 매개변수(parameter)를 가진 모델을 훈련함
- (그러니까 우리는 더 large 한 LM을 효율적으로 학습하고 성능도 좋고 기술의 발전을 이뤄냈다는 뭐 그런 자랑 같음)
결론적으로
- 우리의 GPT-2와 BERT는 특정 데이터셋에서 SOTA 달성함
1. Introduction
NLP는 컴퓨팅 파워와 데이터 크기에 비례해
- 빠르게 발전 중임
즉, 풍부한 컴퓨팅 파워와 데이터는
- unsupervised pretraining을 통해서 점점 더 큰 모델을 학습할 수 있음
우리 경험으로 알 수 있듯이, 더 큰 언어 모델은 다양한 NLP tasks에서 매우 유용한 것을 알 수 있었고
- 최근 연구들도 더 큰 모델을 downstream task에 적용해서 SOTA를 달성하고 있음
이렇게 계속 모델이 커질수록
- 좋은 메모리 관리 기술이 필요함
Adam같이 많이 사용되는 optimization들은 효과적으로 학습하기 위해서는 매개변수랑 추가적인 메모리가 필요함
- 따라서 메모리가 제한적일 경우, 효율적으로 학습할 수 있는 모델의 크기는 작아질 수밖에 없음
모델 병렬 처리에 관한 방법 중 몇 가지는 weights와 관련 옵티마이저 상태가 메모리에 동시에 올라오지 않게 해서
- 메모리 한계 문제를 어느 정도 해결함
예를 들어, GPipe나 Mesh-Tensorlfow 같이 병렬 처리를 위한 프레임워크를 제공하지만,
- 모델을 다시 작성해야 하며, 컴파일러와 프레임 워크에 의존성이 높음
따라서 본 논문에서는
- 이를 해결하기 위한 방법으로 intra-layer model-parallelism 사용한, 간단하고 효율적인 모델 병렬 처리 방법을 보여줌
우리는 특정한 컴파일러 필요 없이 Transformer 기반 LM의 고유한 구조를 이용해 Pytorch로 병렬 구현함
우리 방식의 성능을 보여주기 위한 실험에서,
- baseline은 단일 NVIDIA V100 32GB GPU(39 TeraFLOPs)에서 12억 개의 parameters를 가진 모델을 훈련하는 것을 기준으로 함
여기서 8-way 모델 병렬 처리를 적용하고
- 512개의 GPU에서 parameter가 83억 개를 가진 모델로 확장하면, 우리는 초당 15.1 PetaFLOPs까지 달성함
이 결과는 단일 GPU일 때보다,
- 무려, 76%나 효율적이라는 말임. 결과는 그림 1에서 확인 가능함

또한, 모델 크기 조정이 정확도에 미치는 영향을 분석하기 위해
- Bidirectional BERT랑 LTR GPT-2 둘 다 학습하고 downstream task에 적용해봄
우리는 기존 BERT는 크기가 커질수록
- 모델 성능이 저하되는 것을 확인함
이 문제를 해결하려고, transformer layers에서 아래 2가지를 변화시켰음
- layer normalization
- residual connection
결과는, 모델 크기와 모델 성능이 비례했고, 특정 데이터셋에서 SOTA 달성함
아무튼 요약하자면
- 기존 pytorch만으로 간단하고 효율적으로 모델 병렬 처리 가능!
- 모델 병렬 처리랑 데이터 병렬 처리에 관한 분석을 수행하고 512개 GPU를 사용한 실험에서 76% 효율성을 입증함!
- 모델 크기와 성능이 비례하기 위해선, BERT 같은 모델에서는 placement of layer normalization이 중요한 것을 보여줌!
- WikiText103, LAMBADA, RACE에서 SOTA 달성함!
2. Background and Challenges
2.1 Neural Language Model Pretraining
이제는 Nlp researchers에게는 pretrained language model은 필수적인 부분이 되었고,
- 매우 큰 corpus를 학습에 잘 사용하는 것, 또한 활발한 연구 영역임
이러한 연구들로 인해,
- 단순히 word embedding만을 사용하는 방법에서 지금은 수십억 개의 parameter를 사용하는 방법까지 발전했음
이런 발전 때문에
- 학습 규모에 맞게 효율적으로 작동하는 하드웨어, 시스템과 프레임워크가 필요하게 되었음
우리는 이러한 추세에서 한 단계 더 나아가는데 필요한 방법을 제공하고자 함
2.2 Transformer Language Models and Multi-Head Attention
현재 NLP 트렌드는 transformer를 사용하는 것임. 이유는
- 우수한 정확도와 계산 효율성
원래 Transformer 아키텍처는 인코더-디코더 구조로 설계되었는데,
- 요즘 BERT나 GPT-2 보면, 인코더 아니면 디코더만 사용했음
우리는 아래 2가지 아키텍처에 대해 실험했음
- 디코더 아키텍처인 GPT-2
- 인코더 아키텍쳐인 BERT
2가지 모델을 사용한 이유는, 기존 Transformer 모델과는 다르게
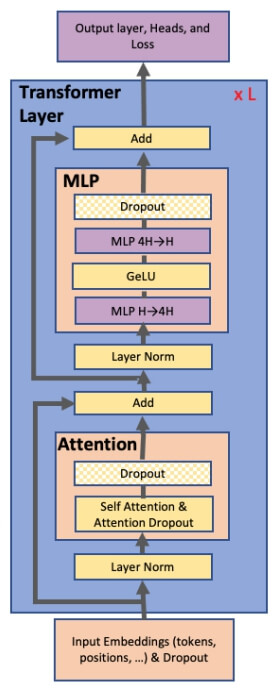
- multi-head attention과 feed forward layers의 입력 부분에서 비선형 함수인 GeLU와 layer normalization를 사용함
- 그림 2는 우리가 사용한 모델의 schematic diagram
2.3 Data and Model Parallelism in Deep Learning
수많은 hardware accelerator로 deep neural network를 학습하기 위한
- 중심이 되는 2가지 패러다임이 있음
Data parallelism
- 학습 batch가 multiple workers에 의해 분할되는 병렬 처리방법
Model parallelism
- 메모리 사용과 연산이 multiple workers에 의해 분할되는 병렬 처리 방법
따라서 multiple worker의 수에 비례해서 batch size 늘리면,
- 학습 데이터 처리량이 선형적으로 늘어남
하지만, 계속 커지는 batch size에 따른 batch training은
- 최적화 과정에서 복잡성을 초래해, 오히려 정확도가 낮아지거나 최적화가 잘 안 될 수도 있음
추가적인 연구에서는 이러한 점을 개선하고
- 큰 뉴럴 네트워크의 훈련 시간을 단축하는 기술을 개발함
훈련 성능을 높이기 위해, parallel work는 아래 두 가지를 결합했음
- data parallelism
- activation checkpointing
- 즉, 메모리 소비를 줄이기 위해, backward pass에서 activation을 다시 계산함
- forward pass에서의 activation 계산은 저장하지 않음
하지만, 이 기술에는 근본적인 한계점이 있음. 이게 뭐냐면
- 하나의 worker에 할당되는 batch size가 적절해야 한다는 것임
BERT나 GTP-2 같은 언어 모델은
- 최신의 하드웨어 가속기를 사용해서 메모리 한계 문제를 해결하고자 했음
사실 이러한 문제를 해결하는 한 가지 방법은
- parameter sharing 기법을 사용해 메모리 사용을 줄이는 것이지만, 이 방법은 모델의 전체 크기를 제한함
우리 방법은 여러 개의 accelerators를 사용해서
- 모델을 분할하여 병렬 처리했음
이 방법의 효과로는
- memory pressure를 줄이고, 병렬 처리량을 증가시킴
모델 병렬 처리에는 2가지 패러다임이 있음
- layer-wise pipeline parallelism
- 보다 일반적인 distributed tensor computation
하지만 이런 기존 패러다임들은
- 특정 문제가 있거나, 지정된 프레임워크를 써야 하는 문제가 있었음
하지만, 우리는 새로운 컴파일러 & 지정된 프레임워크 안 쓰고
- Pytorch만으로도 구현할 수 있음
3. Model Parallel Transformers
챕터 3은 아래 3가지 이유로 생략하였습니다. (사실 다 같은 말)
1. 수준에서 이해하기에는 너무 어려운 영역
2. 공부 목적이 엔지니어의 영역을 너무 벗어난다고 생각
3. 부족한 이해로 인한 잘못된 정보 전달로 이어지는 문제
??? : "그냥 어려워서 못한다는 거 아님?"
"맞다"
아무튼 요약하자면
- 우리 방식은 매우 간단하며 효율적임!
4. Setup
이번 섹션에서는 모델에 대한 구성을 설명함
- 이번 연구에서는 LTR GPT-2랑 BERT만을 사용했음
4.1 Training Dataset
우리는 장기 의존성이 있는 데이터를 다양하게 사용하려고, 큰 데이터셋인
- Wikipedia , CC-Stories , RealNews , OpenWebtext 사용했음
WikiText103에 대해서 테스트할 때, 학습 데이터셋이랑 테스트 데이터셋 같으면 안 되니까
- WikiText103이랑 Wikipedia랑 중복되는 기사 삭제함
CC-Stories 데이터셋에서는
- 불필요한 개행(newlines) 삭제함
BERT 모델은 추가로 BooksCorpus 데이터셋도 사용하지만
- GPT-2는 사용 안 함
데이터 세트는 모두 합쳐서 사용하고
- max_length는 128 token으로 했음
유사한 데이터를 제거하기 위해
- 자카드 유사도가 0.7보다 크면 중복으로 간주해서 제거함
결과는 174GB의 데이터셋을 사용함
4.2 Training Optimization and Hyperparameters
우리는 dynamic loss scaling을 사용한
- mixed precision training방식을 이용함
정규분포 W ~ N(0, 0.02)을 따르도록 W(Weight) 초기화하고
- residual block 앞의 가중치는 1/sqrt(2N)으로 조정함
- N : the number of transformer layers (self-attention과 MLP blocks으로 구성된)
추가 사항(공통)
- 옵티마이져는 Adam사용(decay , λ = 0.01)
- 1.0 global gradient norm clipping 사용
- 0.1 드롭아웃 사용
- 모든 transformer layer 뒤에는 activation checkpointing
모델별 추가 사항
GPT-2
- 30K itreations
- 512 batch size
- 한 문장 최대 토큰 수 1024
BERT
- 기본적으로 ALBERT의 학습 환경과 동일하게 함
- vocab 크기가 30522(원본 BERT에서 사용한 것과 동일)
- NSP(next sentence prediction) 사용하지 않고 ALBERT에서 제안한 SOP(sentence order prediction) 사용함
- SpanBERT에서 사용한 전체 단어를 n-gram 마스킹하는 방식도 사용함
- 1024 batch size
- 200만 회 이상 Iteration
5. Experiments
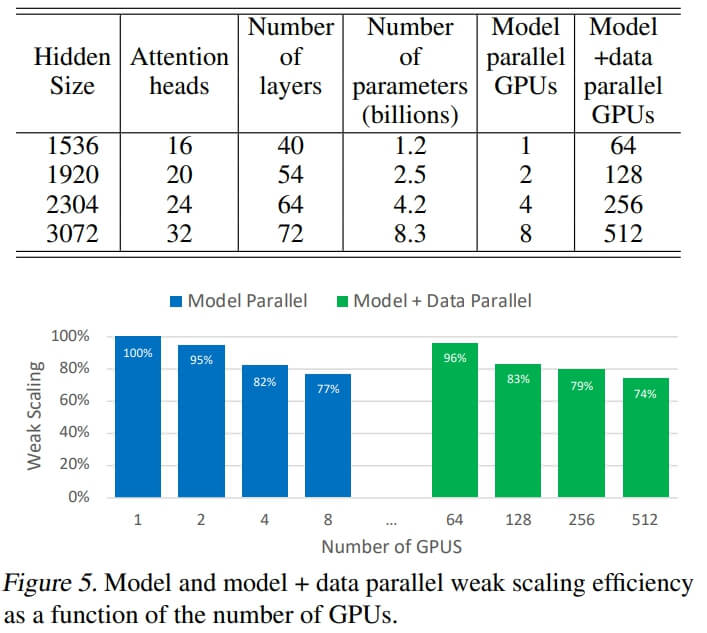
모든 실험은 최대 32개의 DGX-2H 서버, 즉
- 총 512개 Tesla V100 SXM3 32GB GPU를 사용하는 환경임
Model and Data Parallelism scaling result
아래 두 가지 경우를 비교했음
- 모델 병렬 처리만 사용한 스케일링
- 모델과 데이터 병렬 처리를 사용한 종단 간 스케일링(End-to-end scaling)
결과는
- 대형 모델을 현실적인 시간 내에 훈련하는 게 가능하다는 걸 보여줬고
- 다양한 병렬 처리 전략을 스마트하게 결합해서 더욱 빠르게 훈련시킬 수 있는 것을 보여줬음
6. Conclusion
이번 연구에서는
- Pytorch기반 Transformer를 약간만 수정해서 모델 병렬 처리를 구현했고 결과는 성공적이었음
8-way 모델 병렬 처리를 사용해
- 모델을 매우 효율적으로 학습함
BERT 실험하면서
- placement of layer normalization이 모델의 정확도에 중요한 역할한다는 것을 알 수 있었음
WikiText103, LAMBDADA, RACE Task에서
- SOTA 달성함



