[논문 공부] Character Region Awareness for Text Detection
원문 : https://arxiv.org/abs/1904.01941
Character Region Awareness for Text Detection
Scene text detection methods based on neural networks have emerged recently and have shown promising results. Previous methods trained with rigid word-level bounding boxes exhibit limitations in representing the text region in an arbitrary shape. In this p
arxiv.org
개요
이번 포스팅에서는 Character Region Awareness for Text Detection 논문을 공부합니다.
나는 사용했다. 번역을 위해서 구글 번역기
Reference
- hellownd님의 CRFAT 리뷰
- 강준영님의 CRAFT 리뷰
- 오란지님의 CRAFT 리뷰
- ZINO님의 CRAFT 리뷰
- ballentain님의 perspective transformation 설명
들어가기 전
1-stage vs 2-stage
- Detector에서는 2가지의 task를 해결해야 함.
- 해당 물체가 어딨는지 찾는 localization
- 찾은 물체가 어떤 물체인지 분류하는 classification
- 1-stage와 2-stage 방식의 차이점은 위 2가지를 한 단계에 걸쳤냐 2단계에 걸쳤냐의 차이점
TITLE : Character Region Awareness for Text Detection
Abstract
최근에 신경망에 기반한
- Scene text detection 방식이 좋은 결과를 보여주고 있음
이전 논문들의 아쉬운 점은
- word 단위로 bounding boxes를 그리다 보니 텍스트 영역을 표현하는데 한계가 있었음
본 논문에서 새로운 Scene text detection방식을 제안함. 이것은
- character-character 사이의 친화도(affinity) 탐색하여 텍스트 영역을 표현하는 방식임
character-level annotations이 부족해서, 아래 2가지를 활용함
- 합성된 이미지에 대한 character-level annotations
- character-level ground-truths(학습된 중간 모델이 진짜 이미지를 추정한 결과)
Character 사이의 친화도(affinity)를 계산하려면
- 새로운 representation 방식을 사용해야 함
6개의 데이터셋에서 SOTA를 달성했고
- 우리 방식이 다양한 모양의 텍스트( arbitrarily-oriented, curved, or deformed texts)에서도 성능이 좋다고 보장함
1. Introduction
Scene text detection(글자 영역 찾기)는 많은 관심을 받았음. 그 이유는
- 다양한 응용 프로그램으로 활용 가능하기 때문임. (Like, 이미지 검색, 장면 분석 등등)
최근 연구에서는 딥러닝 기반인 Scene text detection이 좋은 성능을 내고 있는 걸 볼 수 있고
- 주로 단어 단위(word-level)로 bounding box를 사용해서 신경망을 학습함
하지만, 단어 단위(word-level)를 사용하는 경우
- 텍스트가 휘거나(curved), 변형되었거나(deformed), 너무 길거나(extremely long) 같은 상황에서 단일 bounding box로 나타내는 것은 좀 어려울 수 있음
대안으로, 문자 단위(Character-level)를 사용하면
- bottom-up방식으로 연속적인 문자들을 하나의 텍스트로 연결할 때 이점이 많음
하지만, 문자 단위(Character-level)로 annotation 된 데이터셋이 많이 없고
- 얻으려면 cost도 너무 많이 듬ㅋㅋ
본 논문에서, 우리는 새로운 text detector를 제안함. 이 detector는
- 문자 단위로 찾고 문자들을 연결해서 텍스트를 찾는 방식임
우리는 detector이름을
- CARFT(Character Region Awareness For Text detection)라고 정함
CRAFT는 CNN 기반 framework이며, 학습할 때 아래 2가지 score를 사용함
1. Region score: 이미지에서 각각의 문자 위치를 찾는 데 사용하는 score
2. Affinity score: 각 문자를 연결해 하나의 텍스트 단위로 그룹화하는 데 사용하는 score
부족한 문자 단위 annotations을 해결하기 위해
- weakly supervised learning framework를 사용했음
이 weakly supervised learning framework은
- word-level 데이터셋에서 character-level 단위 ground truth를 만드는 데 사용함
- (character-level로 annotations 된 데이터셋이 없으니까, 예측 결과를 annotation으로 썼다는 말)
아래 그림 1은 CRAFT의 결과이고 좋은 거 보이지?

그리고 6개 데이터셋에서 SOTA도 달성함
2. Related Work
Regression-based text detectors
object detectors에서 사용하는 box regression을
- 다양한 text detectors에서도 사용하는 방식이 많이 제안되고 있음
텍스트는 일반적으로 물체랑 다르게 불규칙한 모양을 가지고 있음. 이를 해결하기 위해
- 여러 논문에서는 convolutional kernels, anchor boxes, sliding windows를 변형시킴
최근에는 convolutional filters를 변형한 방식인
- RSDD(Rotation-Sensitive Regression Detector)가 나왔음
하지만 결국 이러한 접근법들은
- 많은 다양한 모양의 text를 캡처하는데 한계가 있음
Segmentation-based text detectors
다른 방식으로는 픽셀 수준에서 text를 찾기 위해서
- segmentation에 기반한 방식임
관련 연구로는
단어의 bounding aread를 예측해서 텍스트를 탐지하는 연구
- Multi-scale FCN, Holistic-prediction
Background 영역을 줄여서 text 영역을 강조하는 Attention 메커니즘을 사용한 연구
- SSTD
Text region과 center line을 사용해 텍스트를 탐지하는 연구
- TextSnake
End-to-end text detectors
End-to-end 방식은 Detection/Recognition 모듈을 동시에 훈련해서
- Recognition결과를 활용해서 Detection 정확도를 강화시킴
Recognition module를 학습할 때, 해당 텍스트랑 유사한 배경일 경우
- 텍스트를 더 잘 찾는 건 명백해졌음
사진 속 단어들은 공백, 의미, 색상과 같은 기준으로 구분될 수 있기 때문에
- 대부분의 방식이 Word단위로 Text를 탐지할 때 해당 word의 범위를 설정하는 것은 매우 어려움
그렇기 때문에 word segmentation의 경계(boundary)를 명확하게 정의할 수 없음
Character-level text detectors
한 연구에서는 MSER를 사용한 Character level detector을 제안했지만
- 하지만 MSER를 사용한다는 점에서 낮은 대비, 곡률 및 빛 반사 같은 상황에서 성능이 제한적이었음
Mask TextSpotter detector가 문자 단위로 예측하지만
- 개별 문자를 인식하는 것 대신에 text recognition 하는 데 사용되었음
WordSup detector은 문자 단위로 학습하기 위해
- Weakly supervised framework를 사용했는데, CRAFT는 여기서 idea를 얻었음
그러나 Wordsup의 단점은
- 직사각형의 앵커 박스를 사용하기 때문에 다양한 시점에서 변형되는 문자 모양에 취약함
- backbone으로 SSD를 사용하고 있어서 성능이 제한적임
3. Methodology
우리의 주요 목표는
- Natural images에서 character 위치를 정확하게 찾아내는 것임
이를 위해서
- character regions와 characters사이의 affinity(친화도)를 사용해 신경망을 학습함
Character level의 데이터셋이 없어서
- CRAFT는 weakly supervised방식으로 학습됨
3.1 Architecture
CRAFT의 backbone으로
- VGG16+batch normalization 네트워크 구조 사용함
우리 모델은 decoding part에서
- skip connections을 사용하며, 이는 U-net과 비슷함
최종 output은
- region score와 affinity score , 총 2 channel
아래 그림 2는 우리 네트워크 다이어그램임
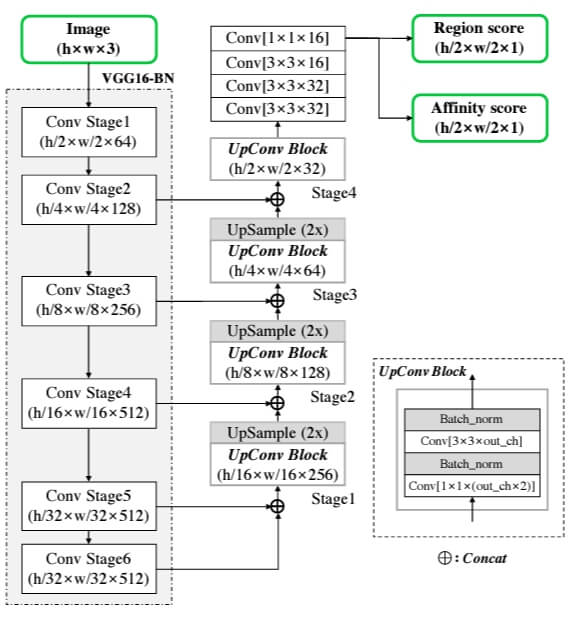
3.2 Training
3.2.1 Gound Truth Label Generation
각 이미지를 학습할 때 필요한, gorund truth label을 생성함
- 생성할 때는 region score & affinity score를 사용함
Region score
- 주어진 픽셀이 문자의 중심에 위치할 확률
- (즉, 그림 3에서 문자 p, e에 해당하는 픽셀이 character box의 center of a character box일 확률
= 이 픽셀이 character인가?)

Affinity score
- 주어진 픽셀이 문자 사이의 공간의 중심 확률
Affinity score를 계산하기 위해서는 Affinity box가 필요한데,
- 각 문자 단위 bounding box를 대각선으로 나누고 생긴 2개의 삼각형의 중심점을 서로 연결함
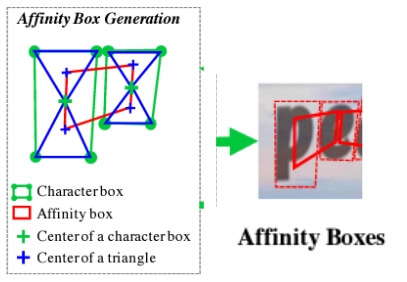
그러고 각 픽셀을 Gaussian heatmap으로 인코딩함
하지만 매번 Gaussian 분포를 계산하는 것은 많은 비용이 들어서 아래 단계를 거쳤음(그림 5)
- 2-dimensional isotropic Gaussian map 생성
- 각각의 Gaussian map과 각각의 character box의 perspective transform 계산함
- Gaussain map을 box로 warp 함
(즉, box 계산 -> 2D Gaussian을 box에 맞게 변형)
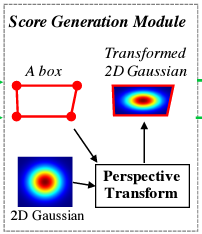
즉, region score map에 문자의 bounding box(character box)으로
- 변형한 gaussian heatmap으로 할당함
그리고, character box가 있으면 affinity box도 구할 수 있으니,
- Affinity score map에 해당 bounding box(affinity box)에 해당하는 좌표를 변형한 gaussian heatmap으로 할당함
아래는 label 생성 파이프라인의 요약 그림
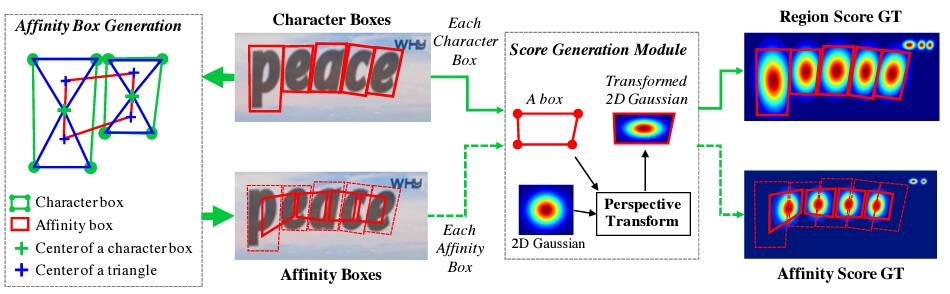
3.2.2 Weakly-Supervised Learning
대부분의 데이터셋이 word-level annotation만 제공하기 때문에
- 우리는 word-level annotation에서 weakly supervised 방식을 사용해 character-level annotation을 생성할 것임(그림 7)
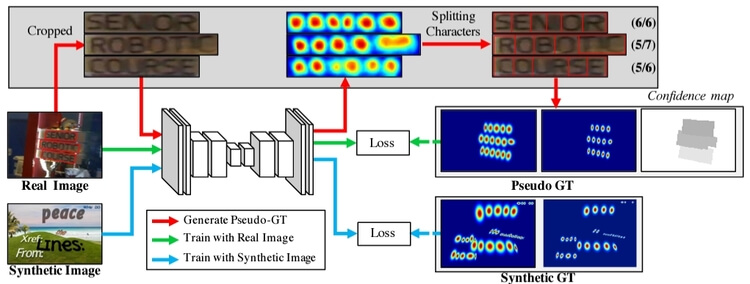
word-level annotation을 입력값으로, 중간 단계 모델(interim model)은
- Cropped 된 단어 이미지에서 character region score를 예측해서 문자 단위 bounding box를 생성함
중간 단계 모델(interim model)의 예측의 신뢰도는
- 감지된 문자의 수를 ground truth의 수로 나눈 값이며, 이는 learning weight로 사용함
그림 7은 character-level로 분할하는 전체 과정이며, 단계는 아래와 같음
- Real image에서 word-level images를 잘라냄(cropped)
- Interim model이 cropped image에 대해서 region score를 예측함
- Watershed algorithm을 사용해서 각각의 Character region으로 분할 하고 characterbox를 만듦
- Charter box는 crop전 Real image의 해당하는 좌표로 이동시킴
당연하겠지만, character box 구했으니,
- Region score & affinity score를 사용한 pseudo-ground truth label도 당연히 만들 수 있겠지(그림 6)?
GT(ground truth) 앞에 pseudo를 왜 붙음?
완전한 모델로 예측하는 것이 아니라 중간 단계 모델을 사용해 GT를 예측하다 보니
GT는 실제 정답과 다를 수 있음, 이를 불완전한 ground truth(pseudo-GTs)라고 표현함
따라서 Weak-supervision을 사용해 모델을 학습 중이라면, pseudo-GTs를 사용해서 학습하는 것임
그러면 이 pseudo-GTs의 신뢰도를 반영하면
- 불완전에서 완전 해 질 수 있겠지?
예측한 단어의 길이를 사용해서 신뢰도를 평가하며, 평가 방법은 아래와 같음
1. 먼저 confidence score를 계산함
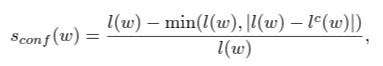
- s_conf(w) : 샘플에 대한 confidence score
- l(w) : 실제 단어 길이
- l^c(w) : 예측한 단어 길이
예를 들자면

- ROBOTIC이란 7개의 문자를 가진 단어를 5개의 checkbox로 예측했으면, confidence score는 5/7
2. 각각의 이미지에 대한 confidence map생성
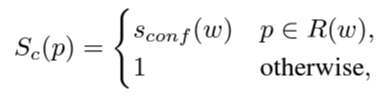
Real image에서 word의 위치에 픽셀(p)의 위치가 포함된다면,
- 픽셀(p)의 위치와 매핑되는 confidence map 값은 confidence score
- 아니면 1
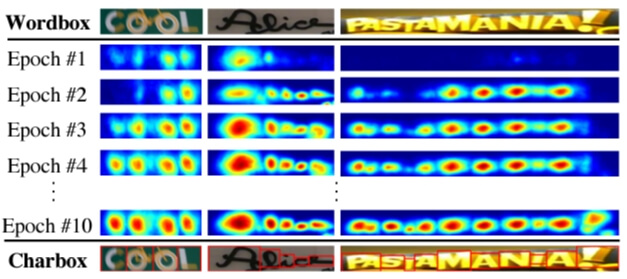
이런 방식으로 학습하게 되면
- CRAFT는 점점 더 정확해지며 confidence scores로 올라갈 것임(아래 그림 8과 보셈)
3.3 Inference
Inference(추론) 단계에서 최종 출력은
- word boxes , character boxes, further polygons의 다양한 모양으로 전달될 수 있음
4. Experiment
사용한 데이터셋
- ICDAR2013
- ICDAR2015
- ICDAR2017
- MSRA-TD500
- TotalText
- CTW-1500
Training strateg(학습전략)
1. SynthText 데이터셋을 50000번 학습 후
- 다른 평가를 위한 데이터셋으로 fine-tune
2. ICDAR 2015, 2017 데이터 세트 중, "DO NOT CARE"는 학습에서 제외
3. Adam optimizer 사용
4. Multi-gpu 학습인 경우
- Training gpu와 Supervision gpu는 분리해서 사용함
5. Supervision gpu를 사용해 Pseudo-GTs를 생성하며 메모리에 저장됨
6. Fine-tuning 할 때,
- SynthText 데이터셋도 1:5 비율로 같이 사용됨
7. 텍스트와 유사한 오브젝트를 걸러내기 위해,
- 1:3 비율로 On-line Hard Negative Mining 적용
8. 기본적인 Data augmentation 기술도 적용함
- Like crops, rotations, color variations, 쿠엑
9. Weakly-supervised 학습에는 2 types data가 필요함
- Quadrilateral annotations for cropping word images
- Transcriptions for calculating word length
- ICDAR2013, 2015, 2017 데이터셋만 위 2 types를 만족함
- 따라서 ICDAR 데이터셋만 CRAFT 훈련하고, 나머지는 fine-tuning 없이 테스트함
- Fine-tune iteration은 25000번
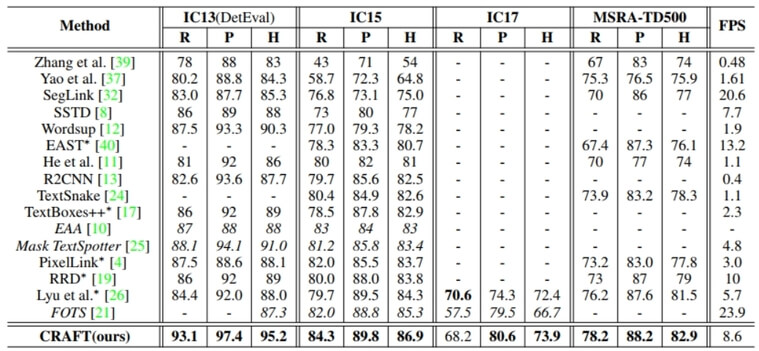
결과
- CARFT는 다른 방법들보다 짱임
5. Conclusion
우리는 character level annotations 없이 character를 찾아내는
- CARFT라는 새로운 text detector를 제안했음
CRAFT는 bottom-up 방식으로 다양한 모양의 텍스트를 찾아낼 수 있게
- region score와 affinity score를 제공함
문자 단위 데이터셋이 거의 없는 문제 때문에
- weakly supervised learning 방식으로 해결함
CRAFT는 대부분 데이터셋에서 SOTA 달성했고
- 나중에는 end-to-end 방식으로 학습하길 희망함



