[논문 공부] What Is Wrong With Scene Text Recognition Model Comparisons Dataset and Model Analysis
원문 : https://arxiv.org/abs/1904.01906
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
Many new proposals for scene text recognition (STR) models have been introduced in recent years. While each claim to have pushed the boundary of the technology, a holistic and fair comparison has been largely missing in the field due to the inconsistent ch
arxiv.org
개요
이번 포스팅에서는 What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis 논문을 공부합니다.
나는 사용했다. 번역을 위해서 구글 번역기
Reference
들어가기전
TITLE : What Is Wrong With Scene Text Recognition Model Comparisons Dataset and Model Analysis
Abstract
Scene text recognition(STR) 모델에 대한 많은 연구가 제안되고, 각각의 모델이 좋다고 말하지만
- 일관성 없는 훈련&평가 데이터셋 대문에 비교를 하는 것은 쉽지 않음
본 논문에서는 이러한 문제를 3가지 주요한 3가지의 Contribution으로 해결함
- 첫째, 학습/훈련 데이터의 불일치를 검사하고, 불일치로 인한 성능 결과의 차이를 조사함
- 둘째, 4단계 STR 프레임 워크 제안함. 이 프레임 워크는 이전의 STR 모델들을 광범위한 영역에서 평가할 수 있음
- 셋째, 일관성 있는 학습/훈련 데이터 사용해서 다양한 평가 진행함
- 1. Introduction
일상적인 사진 혹인 이미지에서 텍스트를 읽는 STR은
- 다양한 분야에서 중요하게 사용되고 있음
OCR 기술이 정형화된 문서에서는 매우 성공적이었지만
- STR(Scene text recognition) 분야에서는 여러 가지 이유 때문에 그다지 효과적이지 않았음
이를 해결하기 위해 여러 방식들이 제안되었지만, 표 1을 보면 알 수 있듯이,
- 일부 논문들은 다른 훈련/평가 데이터셋 및 평가 환경이 달라서 뭐가 개선된 건지 알기 힘듦
우리는 학습 데이터셋과 평가 데이터셋에서 편차가 존재하는 것을 확인했고
- 이러한 불일치 때문에 모델 간의 공정한 성능 비교를 할 수 없음
앞에서 말했지만, 우리는 3가지 contributions으로 이러한 문제를 해결함
첫째, STR논문에서 일반적으로 사용하는
- 모든 학습/평가 데이터셋을 분석함
- 분석 결과에는 데이터 세트의 불일치와 불일치 원인이 포함되어 있음
- 따라서 표 1처럼 비교할 수 없는 결과가 나타난 것을 보여줌
둘째, 통합 STR 프레임워크를 제안함.
- 구체적으로, STR 모델을 4가지 단계로 나눔
- Transformation, Feature extraction, Sequence modeling, Prediction
- 모듈에 따른 성능 차이도 분석할 수 있게
- 변형을 최대한 할 수 있게 함
셋째, 실험 환경 통일시키고
- 모듈에 따른 정확도, 속도, 메모리 요구량도 비교함
결론적으로, 우리는 이전의 모델들을 엄격하게 평가할 거고
- 성능 좋은 프레임워크도 제안함
2. Dataset Matters in STR
섹션 2에서는, 먼저 이전 연구들에서 사용된
- 다른 훈련/학습 데이터셋 분석하고 불일치를 해결함

우리의 분석은 각 데이터셋의 구성과 활용이 어떻게 다른지 보여주고
- 각 모델의 성능 비교 시 이러한 구성의 불일치로 발생하는 편향을 보여줌(표 1)
- (불일치로 인한 성능 격차를 보려면 섹션 4로 고고링)
2.1 Synthetic datasets for traininig
STR 모델들은 학습할 때, Label 데이터가 부족해서
- 합성 데이터를 사용함
먼저, 최근 STR 논문에서 사용된 인기 있는 합성 데이터 세트 2개 말해줌
- MJSynth (MJ)
- SynthText
이전 연구들은 위 2개에다가 다른 요소들을 조합해서 사용했는데
- 이러한 불일치가 좋은 영향을 미친 지, 안 좋은 영향을 알 수 없음
2.2 Real-word datasets for evaluation
Regular 데이터셋과 Irregular 데이터셋으로 분류하여 소개함
Regular Datasets
IIIT5 K-Words (IIIT)
- 구글 이미지에서 크롤링된 데이터
- 2000개의 학습, 3000개의 평가 이미지로 구성
Street View Text (SVT)
- 구글 Street View에서 수집한 실외 거리 이미지임
- 257개의 학습, 647개의 평가 이미지로 구성
ICDAR2003 (IC03)
- ICDAR 2003 Robust Reading competition을 위해 만들어진 데이터셋
- 1156개의 학습, 1110개의 평가용 이미지로 구성되었지만, 너무 짧거나 영숫자 아닌 문자를 제외하면 1110개의 이미지가 867개로 줄어듦
- 또, 연구자들이 860/867개의 다른 버전의 평가 데이터 세트를 사용했음
ICDAR2013 (IC13)
- ICDAR 2013 Robust Reading competition을 위해 만들어진 데이터셋 (대부분 IC2003 데이터를 계승함)
- 848개의 학습, 1095개의 평가용 이미지로 구성되었지만, 너무 짧거나 영숫자 아닌 문자를 제외하면 1015개로 줄어듦
- 마찬가지로, 연구자들이 857/1015개의 다른 버전의 평가 데이터 세트를 사용했음
Irregular Datasets
ICDAR2015 (IC15)
- ICDAR 2015 Robust Reading competition을 위해 만들어진 데이터셋
- 4468개의 학습, 2077개의 평가용 이미지로 구성
- 이미지에는 노이즈, 저해상도, 흐릿하거나 회전된 부분이 많음
- 마찬가지로, 연구자들이 1811/2077 개의 다른 버전의 평가 데이터 세트를 사용했음
SVT Perspective (SP)
- 구글 Street View에서 수집되었음
- 645개의 평가 이미지
CUTE80 (CT)
- Natural scenes에서 수집되었음
- 평가 데이터셋에 288개의 cropped 이미지가 포함되어있음
- 대부분의 구부러진 텍스트 이미지임
3. STR Framework Analysis
이번 섹션에서 각각의 STR 모델의 공통점에서 파생된
- 4단계로 구성된 STR 프레임워크를 소개하고 각 단계 모듈 기능 설명함
STR은 Computer vision/Sequence prediction Tasks랑 유사해서
- CNN이랑 RNN을 사용해서 많은 성능 향상이 있었음
STR을 위한 CNN+RNN의 결합한 CRNN(Convolutional-Recurrent Neural Network)의 등장함
- 이후, 많은 변형 모델이 제안되었고 현재는 RNN을 생략하거나 Attention기반 디코더도 제안되었음
아무튼, 앞에서 말한 기존 STR 모델에서 파생된 4단계는 아래와 같음

1. Transformation(Trans.)
- STN(Spatial Transformer Network)을 사용해 입력 텍스트 이미지를 정규화함
- 정규화를 함으로써 downstream task에 용이함
- 입력 이미지 X를 X~로 변환함. 즉 자연스러운 이미지는 -> 비정상, 비정상 이미지는 -> 정상 이미지로 변화 줌
- 왜? 최대한 많은 정보를 학습하기 위함임. 이렇게 안 하면,eature extraction 할 때 처음 보는 이미지면, 처음 보는 이미지에 대한 representation을 학습하니까 골 때림
- STN의 변형 모델 TPS를 사용해서 유연하게 이미지에 변화 줌
2. Feature extraction (Feat.)
- 글꼴, 색상, 크기 및 배경 같은 텍스트랑 관련 없는 특징을 억제하고
- 입력 이미지를 문자 인식과 관련된 특성에 초점을 둔 representation 생성
- 우리는 이전 STR에서 사용되었던 3가지 아키텍처 (VGG, RCNN, ResNet)를 연구함
3. Sequence modeling(Seq)
- Sequence of characters에서 문맥 정보를 연산함
- Feature extraction에서 추출한 feature map의 각 column을 시퀀스의 한 프레임으로 사용함
- BiLSTM 사용
4. Prediction(Pred.)
- 문자들을 예측함
- 이전의 STR 연구들을 요약해보면 예측에는 2가지 옵션이 있음
- CTC(Connectionist temporal classification)
- Attn(attention-based sequence prediction)
CTC
고정된(fixed) 수의 features가 주어져도
- 예측할 sequence 수는 고정되어 있지 않고(non-fixed) 변화함
핵심 방법은 각 columns에서 문자(character) 예측하고 반복되는 문자나 공백을 삭제해서,
- Full character sequence을 non-fixed stream of characters로 변화 시킴
Attn
Input sequence에서 정보이론(information flow/theory)을 계산해서 Output sequence를 예측하고
- 이로 인해, 문자 단위(character-level) 모델로 학습이 가능해짐
4. Experiment and Analysis
우리는 표 2처럼 모든 모듈을 다르게 조합해서 24(2*3*2*2) 개의 프레임워크로 실험했음
24개 조합 : (Non/TPS) * (VGG/RCNN/ResNet) * (None/BiLSTM) * (CTC/Attn)
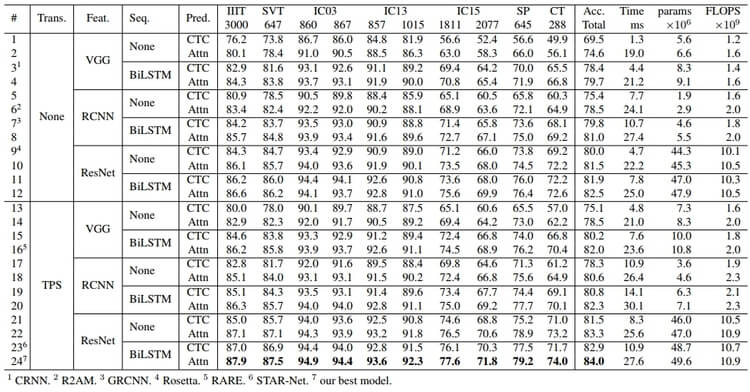
4.1. Implementation detail
STR training and model selection
- Training Dataset : MJSynth(8.9 M) + SynthText(5.5M)
- Validation Dataset : IC13 + IC15 + IIIT + SVT
- Optimizer : AdaDelta(decay p=0.95)
- Batch size : 192
- Itreations : 300k
- Parameters initializing : He
- 2000번 학습마다, 모델 검증함
- 알파벳과 숫자에 대해서만 평가함
- 총 5번 무작위 시드에 대해서 평가하고 정확도 평균냄
- 공정한 속도 비교를 위해 동일한 환경에서 했고, NSML(Naver Smart Machine Learning)에서 수행
4.2 Analysis on traininig datasets
다른 훈련 데이터 세트들이
- 벤치마크 성능에 미치는 영향을 분석함
섹션 2에서 말했지만, 데이터 세트를 계속 조합해서 사용하다 보니
- 뭐가 모델 성능 향상에 영향을 기여한 지 모름
분석 결과로는
- 학습 데이터의 수보다, 학습 데이터의 다양성이 더 중요했음
4.3 Analysis of trade-offs for module combinations
각 기준(정확도, 속도, 메모리)에 따라 중요한 모듈이 다름.
- 따라서 최상의 trade-off를 위해 다양한 모듈 조합을 테스트했음
5. Conclustion
STR(scene text recognition) 모델은 많이 발전했지만
- 일관되지 않은 조건으로 비교가 되어서, 모델 발전에 기여한 요소와 방법을 결정하기 어려웠음
그래서 우리는 주요 STR방법을 매우 일관성 있고 공정하게 비교 분석했고
- 일반적인 문제랑 실패 사례 같은 분석도 했음



