[논문 공부] LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
원문 : https://arxiv.org/abs/2010.01057
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entiti
arxiv.org
개요
이번 포스팅에서는 LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention 논문을 공부합니다.
나는 사용했다. 번역을 위해서 구글 번역기
Reference
들어가기 전
TITLE : LUKE - Deep Contextualized Entity Representations with Entity-aware Self-attention
Abstract
Entity representation은 Entity와 관련된 Task에서
- 매우 유용함(당연한 소리를)
본 논문에서는 양방향 트랜스포머(bidirectional transformer)에 기반한
- entity와 words를 위한 new pre-trained contextualized representations를 제안함
우리 모델은 주어진 텍스트 내에서
- 단어와 객체(words, entities)를 독립적인 tokens으로 사용함
그리고 독립적인 tokens들의
- contextualized representations를 출력함
우리 모델은 new pretraining 방식을 사용해 학습하는데, 이 방식은
- BERT의 MLM(masked language model)에 기반함
이 새로운 방식은
- 무작위로 maksed words와 masked entities를 예측함
- words와 entities는 Wikipedia에서 사용
new pretraining 방식 말고도, 우리는
- Entitiy-aware self-attention mechanism을 제안함
- (기존 트랜스포머에서 사용된 self-attention의 확장된 버전)
그리고 attention scores를 계산할 때,
- Token type이 words인지 entities인지도 계산함
결론적으로 우리 모델은
- entitiy와 관련된 많은 task에서 impressive 한 성능을 달성함
물론, 특정 데이터셋에서는
- SOTA도 달성함
1. Introduction
Relation classification(관계 분류), NER, QA 같은 많은 자연어 tasks들은
- Entities(객체)와 연관되어 있음
당연한 소리를 하자면 이러한, entity와 관련된 tasks를 해결하는 핵심은
- 모델이 entities정보를 효율적으로 학습하는 데 있음
전통적인 entity representations은 각각의 entity를
- 고정된 임베딩 벡터로 할당함
고정된 임베딩 벡터는
- KB(knowledge base)에 저장된 Entity 정보를 가지고 있음
따라서 KB안에 많은 정보가 있지만, 실제로 text에서 entity 정보를 표현하려면
- KB안에 있는 정보와 매핑해주는 entity-linking이 필요하며
- KB안에 정보가 없으면 representation하지 못함
반면에, transformer을 기반으로 하는(BERT나 RoBERTa)
- Contextualized word representation은 잘 일반화된 word representation을 제공함
- 이 representation은 unsupervised 방법에 의해 학습되었음
최근 entity관련 연구들은
- CWRs(contextualized word representations)을 사용하고 있음
하지만!, CWRs의 아키텍처가 entity를 표현하는데 적합하지 않은 이유가 2개 있음
- CWRs는 span-level을 출력하지 않는다
- 많은 entity 관련 tasks는 entity사이의 관계를 추론하는 과정이 있는데 CWRs 방식으로는 어려움이 있음
- 비록 transformer가 self-attention 같은 방법을 사용해서 단어들 사이의 복잡한 관계를 계산할지라도, self-attention 과정에서 많은 entity가 여러 토큰으로 분할되기 때문에 그들 사이의 관계를 추론하기는 쉽지 않음
추가적으로 CWRs의 단어 기반 pretraining 방식은 entity representation을 학습하는데도 적절하지 않음. 왜냐하면
- “The Lord of the [MASK]”이란 문장에서 [MASK]를 “Rings”라고 예측하는 것이 전체 entity를 예측하는 것보다 쉽기 때문임
서론이 길었는데, 아무튼 본 논문에서는 새로운 contextualized representations 방식인
- LUKE를 보여줌
- Language Understanding with Knowledge-based Embeddings
LUKE는 transformer를 기반으로 하며
- Wikipedia의 방대한 양의 corpus로 학습됨. 학습할 때는 entity-annotated도 같이 학습
LUKE랑 기존 CWRs의 주요 차이점은
- LUKE는 entity도 하나의 독립적인 토큰으로 취급함
- 그리고 중간과 출력 representation을 계산함
간략하게 예시를 들자면

만약 “Beyonce lives in Los Angeles.” 문장을 사용한다고 가정하면
- LUKE는 모든 단어와 entity representation을 출력함
- 왼쪽 밑에 보면 Words랑 Entities를 둘 다 pretraining에 사용하는 거 보이지? - LUKE는 maked words나 masked entity를 예측하면서 학습함
LUKE가 entities를 token으로 취급하기 때문에
- Entity 사이의 관계 정보를 가지고 모델링할 수 있음
LUKE는 BERT의 MLM을 확장한 새로운 pretraining 방식으로 학습함
이 새로운 pretraing 방식은
- 임의로 entity를 masking 하고 원본을 예측하는 방법임
우리는 base model로 RoBERTa를 사용하고
- MLM task와 해결할 task 동시에 최적화하는 방향으로 학습함
그리고 downstream에 적용할 때, 해당 task에 맞게 학습된 모델은
- Masked 된 entity에 대한 임의의 entity representation을 계산함
또 다른 주요 핵심은
- 기존 transformer에 entity-aware self-attention 메커니즘을 적용해 확장시킨 것
기존 CWRs랑 다른 점은
- 두 가지 타입의 토큰을 다루는 것임(words & entities)
그렇기 때문에
- 두 가지 타입 유형을 쉽게 결정하는 메커니즘이 중요하다고 생각함
따라서
- 서로 다른 메커니즘을 적용한 기존의 self-attention방식을 향상함
- (이 다른 메커니즘은 attending token과 attended token에 기반함)
소개가 너무 길었는데 아무튼
LUKE 성능은
- RoBERTa를 포함한 모든 베이스 라인 모델들보다 성능이 좋고 특정 5가지 entity task에서는 SOTA 달성함
그래서 Intro를 요약하자면
- LUKE는 Wikipedia데이터셋에서 생성된 코퍼스 데이터셋을 사용하며, 임의로 masking 된 words나 entity를 본래 단어가 뭔지 예측하는 과정으로 학습함. 이는 contextualized representations임
- 기존 트랜스포머의 self-attention을 발전시킨 entity-aware self-attention mechanism을 사용함. 이 메커니즘은 attention scores를 계산하는 과정에서 토큰 타입(words or entities)이 무엇인지 반영함
- LUKE는 SOTA 달성함
2. Related work
2.1. Static Entity Representations
전통적인 방법의 entity representation은
- 각 entity에 해당하는 고정된(fixed) 임베딩을 KB(knowlege base) 내부에 할당함
KB에 할당되는 고정된 임베딩 값이란 아래 두 정보를 포함
- knowledge graphs에 의해 학습된 embeddings
- 문맥과 entity관련 설명문을 사용해 학습된 embeddings
아무튼 KB에 있는 정보를 사용해서 학습함, 반대로 말하면
- KB안에 정보가 없으면 representation 할 수 없고, KB에 매우 의존적이라는 단점을 가짐
2.2. Contextualized Word Representations
최근 많은 연구들은
- Entity 관련 task에 CWRs 사용함(대표적인 예로 ELMO, BERT 있음)
BERT는 random words를 마스킹하고 본래 단어를 예측하는 MLM 방식으로 학습하고
- RoBERTa, XLNet, BART, ALBERT에서 사용되는 CWRs는 MLM방식과 같거나 비슷함
아무튼 많은 방식들이 있는데
- LUKE는 entity-aware self-attention mechanism을 적용한 트랜스포머 아키텍처를 사용함
이 메커니즘은 entity 관련 task에 최적화되어있고
- 성능도 좋음
3. LUKE
그림 1은 LUKE 아키텍처이며
- multi-layer bidirectional transformer구조임
LUKE는 words와 entity를 입력 token으로 사용하고
- 각 token에 대해 representation 값을 계산함
m개의 words랑 n개의 entity로 구성된 문장이 입력으로 들어오면
- 모델은 D-차원의 words embeddings와 entites embedding을 계산함
- m개의 words : w1, w2,... wm
- n개의 entities : e1, e1,.... en
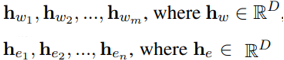
3.1 Input Representation
입력 토큰 임베딩 값은 아래 3가지를 사용해 계산
- Token Embedding
- Position Embedding
- Entity type Embedding
3.1.1. Token Embedding
Token Embedding이란
- 당연하게도 그 토큰을 나타내는 임베딩
토큰 임베딩을 아래 수식으로 정의
- V_w : words vocab 사이즈
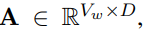
Token Embedding 계산을 효율적으로 하기 위해서
- entity token embedding를 두 개의 small matrices로 나눠서 계산함
- 따라서 entity token embedding은 두 매트릭스를 합친 BU (아래 수식)
- V_e : entity vocab 크기
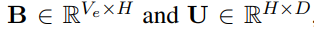
3.1.2. Position Embedding
Position Embedding이란
- 당연하게도 문장에서 해당 단어의 위치 정보에 해당하는 임베딩
문장에서 i번째 위치하는 값을 나타낼 때
- word와 entity는 각각 C_i, D_i로 표시
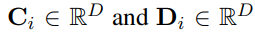
하나의 entity name에 단어 여러 개가 포함된다면
- position embedding 값은 각 단어의 position embedding의 평균을 사용함(그림 1)
- 예를 들자면, Los Angeles는 단어 2개지만 하나의 local entity name임
3.1.3. Entity type Embedding
Entity type embedding 이란
- 해당 토큰이 entity인지 아닌지 임베딩
해당 Embedding은
- single vecotor이며, 아래 수식으로 나타냄
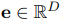
결론적으로 (word와 entity 각각에 해당하는) Input representation은
- Token Emb, Position Emb, Entity Type Emb 모두를 합산하여 계산됨
또한 다른 연구에서도 사용했던
- [CLS]와 [SEP] 토큰을 사용함
3.2 Entity-aware Self-attention
self-attention 메커니즘은
- transformer에서 사용되는 기본 개념임
Input vector(x1, x2... xk)가 주어지면
- 각각의 output vector(y1, y2..., yk)는 transformed input vectors의 가중치 합계에 기반해서 계산하는 그런 방식임
- (아무튼 뭐 그런 거임)
LUKE에서는 이 input vector와 ouput vector가
- word token과 entity token에 해당하며, output vector는 아래 수식처럼 계산됨
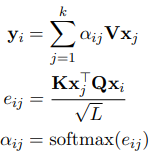
수식을 설명하자면
- k : m+n (m: word 개수, n : entity 개수)
- e_ij : attention scores
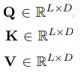
- 각각은 Query, Key, Value를 나타냄
LUKE는 두 가지 타입의 토큰(word or entity)을 처리하기 때문에
- attention score를 계산할 때, target 할 token type 정보를 사용하는 것이 좋다고 생각했음
아무튼 우리는 이렇게 생각해서, entity-aware query mechanism개념을 도입해서
- self-attention 메커니즘을 발전시켰음
이 메커니즘에서는 token type을 하나의 pair로 사용했는데
- 이 pair는 가능한 많이 다르게 구성될 수 있게 생성함
- 즉, token type이 2가지(word or entity)라서 , 4가지의 경우의 수가 나옴
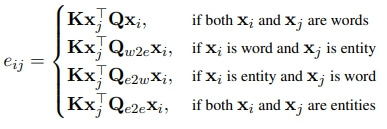
- 아래는 query matrices에 해당하는 수식임
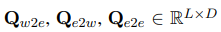
3.3 Pretraining Task
LUKE를 pretrain 하기 위해 우리는 2가지 task를 사용함
- conventional MLM
- new pretraining task (MLM 기능을 확장함. 이유는 entity representation을 학습하기 위함)
특히, Wikipedia에서 하이퍼링크는 entity annotation으로 취급하고
- Wikipedia에서 large corpus를 생성해 모델을 학습함
그리고 특정 비율로 entity를 [Mask]하고
- 예측하는 과정으로 학습하며, 모든 entity에 대해 softmax를 적용해서 예측 결과가 나옴

- h_e는 마스킹된 enttiy에 해당하는 임베딩이며 나머지는 아래와 같음
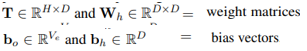
또한 pretrain에서 사용하는 loss function은
- MLM loss와 cross-entropy의 합임
3.4 Modeling Details
LUKE의 configurations은
- RoBERTa large와 동일하게 맞춤
또한 bidirectional transformer를 기반으로 하는데, 이 transformer 구성
- 1024 hidden dimensions
- 24 hidden layers
- 64 attention head dimensions
- 16 self-attention heads
Entity Token의 임베딩 차원
- 256 (H=256)
총 parameters 수는 483M 개
- RoBERTa parameter355M 개
- 추가적으로 우리의 entitiy embedding을 위한 parameters 수 128M 개
사용한 Tokenizer
- RoBERTa Tokenizer
- vocab 사이즈는 50K(V_w = 50K)
Entity vocab 사이즈
- 500K(V_e = 500K)
- Entity vocab에 [Mask], [UNK] 포함
- vocab에 없는 word인 경우, [UNK]로 대체
Train Step
- 200K
Masking percentages
- 전체 word와 entity의 15%
우리의 entity-aware self-attention mechanism은 사용하지 않고
- 기존의 self-attention mechanism 사용함ㅜㅜ
- pretraining 2번 못하겠음. 자세한 내용은 부록 A 확인하셈
5. Analysis
3개의 추가적인 실험을 통해
- LUKE의 자세한 분석 내용을 공유
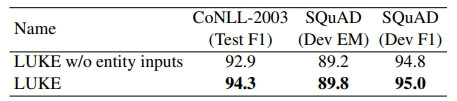
5.1 Effects of Entity Representations
우리의 entity representation가 downstream tasks에 효과가 있는지를 조사하기 위한 2가지 실험함
- CoNLL-2003 데이터셋에서 NER 성능 실험
- SQuAD 데이터셋에서 QA task 실험
여기서 LUKE는 word representation 계산할 때
- word sequence만 사용함
RoBERTa와 동일한 모델 아키텍처 사용함
아래 표에서 알 수 있듯이 entity representation의 효과를 성공적으로 입증함
5.2 Effects of Entity-aware Self-attention
비교 연구를 수행함. 뭐를 비교했냐면
- 우리의 entity-aware self-attention mechanism을 사용한 LUKE
- 본래 transformer의 self-attention을 사용한 LUKE
결론적으로는, 우리 방식이 일관적으로 성능이 좋았음

특히
- Relation Classification이랑 QA task에서 상당한 성능 향상을 보임
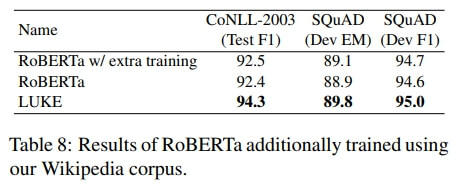
5.3 Effects of Extra Pretraining
저 위에서 말했지만 LUKE는 Wikipedia를 가지고 200k steps 학습했음
하지만 누군가는
- "그냥 학습 많이 해서 LUKE가 RoBERTa보다 성능 좋은 거 아님?ㅋㅋ 주작 멈춰"라고 할 수도 있음
그래서 RoBERTa도 200K steps 학습해서 비교했는데
- 결과적으로 성능이 좋았음
6. Conclusions
본 논문에서는
- new pretrained contextualized representations 방법인 LUKE를 보여줬음
또한
- entity-aware self-attention mechanism이라는 새로운 방식을 사용했고 성능도 입증함
추후에는 LUKE가
- 특수한 도메인 Task(생물, 의학.. 법률)에도 적용할 수 있게 할 것임



