ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
원문 : https://arxiv.org/abs/2003.10555
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, the
arxiv.org
개요
이번 포스팅에서는 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators 논문을 공부합니다.
나는 사용했다. 구글 번역기 번역을 위해서
Reference
yooj_lee님의 Contrastive Learning
TITLE : ELECTRA - Pre-training Text Encoders as Discriminators Rather Than Generators
Abstract
ELECTRA 소개하기 전에
- BERT 같이 특정 토큰을 [Mask] 씌운 후, 해당 Token을 맞추는 방식인 MLM방식을 pretraining단계에서 사용함
하지만 이 방법을 downstream NLP tasks에 적용하기 위해서는
- 상당히 많은 양의 컴퓨팅 파워를 필요로 함
따라서 우리는 이 방법을 대신에
- "Replaced Token Detection"이라 불리는 더욱 효율적인 pretraining 방식을 제안함
RTD에 대해 간략하게 설명하자면
- 입력 Token을 masking 하는 것이 아니라 generator network에서 토큰을 생성해내고, discriminative model이 그것이 original token인지, 아니면 generated token 인지에 대해 학습함
우리는 실험을 통해 해당 방식이 효율적이라고 주장하는데 이유는
- MLM 같이 masked 된 특정 토큰들(subset)이 아니라, 전체 토큰에 대한 정보를 학습하기 때문임
결론적으로 우리 방식은
- BERT보다 좋고 RoBERTa와 XLNet과 비교했을 때 1/4정에 해당하는 컴퓨팅 파워를 사용하고 동일한 파워를 사용하면 더 우수함
1. Introduction
현재 언어 SOTA모델 학습 방식은
- denoising autoencoder 방식이라고 볼 수 있음
여기서 말하는 Denoising autoencoder 방식이란
- unlabeled input sequence에 대해 15% 정도 masking 하거나 XLNet 방식처럼 token에 대해 attention 해서 original token으로 복원하는 방식으로 학습하는 것
이러한 방식은 효과적이지만
- 각각의 example마다 15%만 학습하기 때문에 (== 전체 토큰 중 15% loss 만 학습하기 때문에) 상당한 computing cost를 발생시킴
따라서 다른 방식으로, 새로운 pretraining 방식인 Replaced Token Detection 제안함. 이 방식은
- 실제 input tokens에서 생성된 토큰(genereated replaced token)과 원래 토큰(original token)을 구별하는 task임
마스킹하는 방식 대신에
- 우리는 small masked language model(== generator)의 출력 값(output)으로 대체 토큰을 만들어냄
이 방식은 BERT에서 제안된 [Mask] 토큰이
pre-training 과정에서 사용되지만 fine-tuning 단계에서 사용되지 않는 문제도 해결함
그 후 discriminaor 모델을 학습하는데, 이것은
- 그 replaced token(== generator에서 생성된 토큰)인지 original 토큰인지 구별하는 구별 모델을 pre-train 함
우리 방식의 장점은 BERT같이 작은 masked subset 데이터(입력의 15%)만 학습하는 것이 아니라
- 모든 입력 토큰에 대해 학습함
우리 방법이 GAN과 비슷해 보일 수 있다. 하지만
- GANs를 텍스트에 적용하기는 어렵기 때문에, maximum likelihood를 학습하는 점에서 adversarial하지 않음
따라서 ELECTRA는
- BERT보다 더 빠르게 학습하며 성능도 좋음
이전 연구들을 보면 계산이 많이 질수록(== 모델이 커질수록, 파라미터가 많아질수록) 성능이 계속 좋아지는데
- 제한적인 컴퓨팅 리소스 때문에 효율적으로 계산을 해야 함.
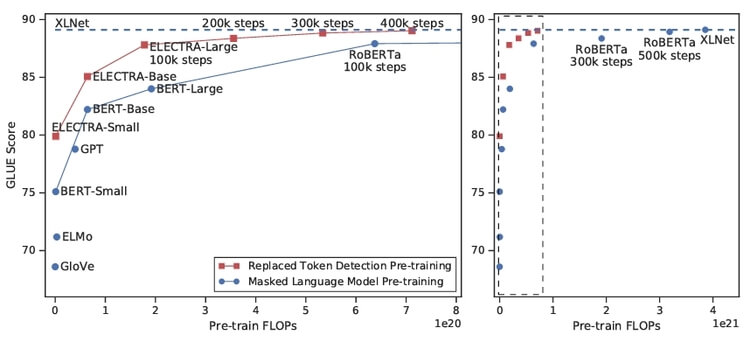
따라서 성능 테스트뿐만 아니라 계산 효율성에 대해서도 실험을 했고(그림 1)
- ELCTRA는 기존 방식들보다 효율적으로(compute-efficient, parameter-efficent) 학습함
2. Method
- RTD(replaced token detection)에 대해 설명함

RTD 방식은 2개의 neural networks를 학습함
- G : Generator
- D : Discriminator
두 개의 neural networks(G, D)는 Transoformer encoder로 구성되며, 이것은
- input tokens( x = [x1,..., xn] )으로 구성된 sequence를 텍스트화 된 벡터 표현(h (x)=[h1,..., hn] )의 sequence로 매핑시킴
그림 2. 수행 순서(수식- 설명)
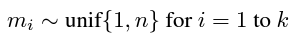
1. Generator는 입력(x= [x1, x2,..., xn] )이 주어지면
- m=[m1,..., mk]을 마스킹함(1부터 n까지 임의 위치 집합을 선택해서 마스킹)
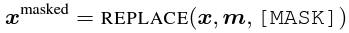
2. 선택된 position의 tokens은 [MASK] token으로 변환함
- 이 값이 Generator의 입력이 됨(그림 2)
- 여기서 Generator는 masked-out tokens의 original identities를 예측하도록 학습
- 즉, Generator는 [Mask] 토큰의 original token을 예측함

3. 그러고 Discriminator는 그것이 대체된 토큰인지 아닌지 구별하도록 학습함
- 즉, Discriminator의 입력값은 Generator가 [Mask] 토큰의 original token을 예측한 값을 입력값으로 사용해서 그것이 original token인지 replaced token인지 구별함
- x_corrupt : discriminator의 입력 값
- x^ : generator의 출력 값
Generator의 최종 수식
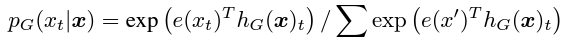
- t : position t (위치 정보)
- e : token embedding
위 수행 순서에서 나온 식을 대입해서 수식을 풀어쓰면
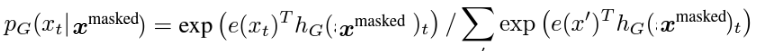
Discriminator 최종 수식
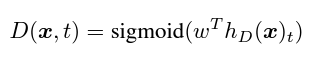
- t : position(위치정보)
- 위 수행 순서에서 나온 식을 대입해서 수식을 풀어쓰면
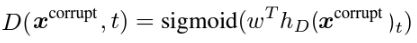
1~m까지 임의의 위치 집합을 선택해서 Masking 하고 학습한다는데 위치 집합을 왜 학습하는가?
위치 정보라는 게 도대체 뭔가요. 그걸 왜 선택하고 학습?
예를 들어, 아래와 같은 4개의 입력 문장이 있음
나는 국밥을 먹었다
나는 김밥을 먹었다.
나는 초밥을 먹었다.
나는 라면을 먹었다.
1번째 위치를 Masking 한다고 하면,
[Mask] 국밥을 먹었다
[Mask] 김밥을 먹었다...
라고 마스킹이 될 것이고
Generator는
1번째에 위치한 [Mask]는 "나는"이라고 학습하게 될 것이다.
그러면
입력 문장 "국밥과 김밥을 먹었다" 은
"[Mask] 김밥을 먹었다"라고 마스킹될 것이고
문장을 예측할 때는 Generator는 위치 정보에 의해
"나는 김밥을 먹었다"
라고 예측을 할 확률이 높다는 것.
위치정보에 의해 학습한다는 것은 위와 같은 방식을 의미함
따라서 Generator는
original token을 real token로 예측하거나
original을 replaced token으로 예측해서
Discriminator의 입력으로 사용하는 것이 해당 방식임
수행 단계 요약
1. 주어진 입력 시퀀스에 대해 일부 토큰을 [Mask] 토큰으로 무작위로 변경함
2. Generator는 모든 [Mask] token에 대한 원래 토큰을 예측함.
3. Discriminator는 Generator의 예측을 입력으로 사용하며, 예측이 replaced인지 original인지 구분함
GAN과 ELECTRA 차이점
Generator가 original token과 동일한 token을 예측하면
- 해당 token은 'fake'가 아니라 'real' 임 (GAN은 'fake'로 간주함)
Generator는 adversarial 하게 학습하는게 아니라
- maxiumum likelihood로 학습함
왜냐하면 Generator를 adversarial하게 학습하는 것이 어렵기 때문임. 이유는
- Generator에서 sampling 과정 때문에 역전파가 불가능함
마지막으로 noise vector를 Generator 입력으로 사용하지 않음
Generator loss와 Discriminator Loss의 합을 최소화하도록 학습하며
- 샘플링 과정 때문에 Discriminator loss는 Generator로 역전파 되지 않음
따라서 pre-training후에는 Generator는 버리고
- Discriminator만 fine-tuning 함
4. Related Work
Generative Adversarial Networks
GAN은 고품질의 합성 데이터를 생성하는데 효과적이고 이전에 우리와 유사한 방식으로 GAN의 Discriminator을 downstream task에 적용한 연구가 있었지만
- 표준 maximum likelihood 학습보다 성능이 안 좋았음
우리는 adversarial 하게 학습하지는 않지만 MaskGAN을 연상시키긴 함 ㅋㅋ
Contrastive Learning
일반적으로, contrastive learning 방식은
- 학습된 표현 공간에서 비슷한 데이터는 가깝게, 다른 데이터는 멀게 존재하도록 표현 공간을 학습함
ELECTRA는 특히 NCE(Noise-Contrastive Estimation)랑 관련이 있음. 이것은
- real point와 fake point를 구별하도록 이진 분류기를 학습함
사실, ELECTRA는 Negative Sampling을 사용한
- CBOW(Continuous Bag of-Words)의 확장 버전으로 볼 수 있음
5. Conclusion
Language representation learning을 위한
- 새로운 self-supervised task인 Replaced Token Detection을 제안함
주요 핵심은
- small generator network에서 생성된 negative sample을 구분하도록 text encoder를 학습하는 것
ELECTRA는 BERT의 MLM보다
- 계산 효율적이고 성능도 더 좋음



