[논문 공부] ELMO : Deep contextualized word representations
원문 : https://arxiv.org/abs/1802.05365
Deep contextualized word representations
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are
arxiv.org
개요
이번 포스팅에서는 ELMO : Deep contextualized word representations 논문을 공부합니다.
나는 사용했다. 번역을 위해서 구글 번역기
Reference
들어가기 전
subwords?(서브 워드란?)
log likelihodd
- 특정 사건들이 일어날 가능성 또는 샘플들과 확률 분포의 일관된 정도에 log를 취한 값
TITLE : ELMO - Deep contextualized word representations
Abstract
- 새로운 형식의 deep contextualized word representation을 소개함
- 이것은 syntax, semantics와 다의어를 모두 고려한 representation방법임
- Deep bidirectional language model(biLM)의 중간 state를 이용해 단어를 임베딩 하는 방식
- 이 방식은 기존 모델에 쉽게 적용해서 사용할 수 있음
- 6개 분야에서 SOTA 달성
1. Introduction
- NLU 모델 핵심 요소/문제는
- Pre-trained word representation(like Word2vec) 은 NLU 모델의 핵심 구성 요소임
- High quality 한 word representations를 학습하는 것은 단어의 여러 특성(다의어, 복잡성)때문에 매우 어려운 문제임
- 위 요소/문제를 해결하기 위해 우리는
- 본 논문에서는 위 2가지 문제(요소)를 해결하고, 기존 모델에 적용 가능하며 다양한 NLU taks에 걸친 문제를 개선할 수 있는 deep contextualized word representation을 소개함
- 기존 방식과의 차이점은
- 전체 input sentence에서 각 token을 임베딩을 하는 것임
- Bidirectional LSTM에서 파생된 vector를 사용하며, 이때 LSTM은 language model(번역 모델)을 목표로 학습됨
- 따라서 이것을 ELMo라고 부르기로 함
- 마지막으로 자랑 좀 하자면
- ELMO는 biLM의 내부 layer를 모두 사용하기 때문에 deep 하다고 말하며, 최상단 Layer만 사용하는 LSTM보다 성능 좋았음
- 이러한 내부의 레이어 상태/정보(internal states)를 전부 사용하는 방식은 LSTM보다 문맥에서 단어 의미를 더 잘 찾고 문법적인 관점에서의 상태를 더 잘 찾아냄
요약 : LM에 focused 된 LSTM에서 나온 Vector를 가지고 학습한 ELMo 소개함
2. Related work
- NLP Task 문제 해결에서 기준이 되는 구성요소는
- pretrained word vectors는 규모가 큰 unlabeled text에서 syntactic 하고 semantic 정보를 잡아낼 수 있기 때문에 SOTA NLP 아키텍처 구성요소의 표준이 됨
- 기준이 되는 구성요소에 접근하기 위한 우리 방법은
- 우리는 character 합성곱을 사용해 subwords에서 정보를 얻고 predefined 된 sense(의미) 클래스만을 예측하려고 명확하게 학습하지 않고, multi-sense의 정보로 downstream task에 적절하게 통합해 학습함
- 최근 연구는
- 최근 다른 연구는 LSTM을 사용한 context2vec에 초점이 맞춰저있음
- 다른 연구로는 pivot word자체가 Embedding에 포함돼서 비지도 언어 모델이나 자연어 번역 시스템(MT)에서 같이 인코딩 되는 방법이 있음
- 위 두 방법은 큰 데이터셋에서 성능이 향상되었음
- 따라서 우리는
- 본 논문에서는 위와 같은 접근법을 최대한 활용하며, 30 million개의 문장으로 우리의 biLM을 학습함
- biLM 임베딩은 방식은 다양한 NLP Task에 적용 가능하도록 일반화시켰음
요약 : 우리 말고 좋다고 하는 방식들 장점 최대한 반영한 biLM, ELMo 소개함
3. ELMo : Embeddings from Language Models
- 다른 임베딩 방식과는 다르게
- ELMo는 전체 입력 문장에 대해서 각 단어를 임베딩 하는 방식임
- 따라서 각 단어를 임베딩 계산을 하기 위해서
- 내부 states를 반영하는 선형 계산으로 character convolutions을 사용하며 2개 층의 biLM을 사용해 계산함
- 이러한 계산 방식의 장점은
- semi-supervised learning(준지도 학습)을 수행할 수 있는데, 이것은 biLM이 대규모 데이터셋에 사용되고 기존 NLP 아키텍처에 쉽게 적용이 가능하기 때문임
3.1 Bidirectional language Models
여기서 말하는 양방향(Bidirectional)이란 Forward + Backward 개념임
Tip
BERT 논문에서는 ELMo는 양방향이라고 말하지만 사실상 단방향(LTR)+단방향(RTL)이 합쳐진 양방향이라고 말하며, 단일 양방향(a single bidirectional) 모델보다 2배의 계산비용이 더 들어간다고 말함
Forward LSTM
- N개의 Token으로 구성된 Sequnece를 입력 받음

- N개의 Token(t_1, t_2... t_N)이 입력값으로 주어진다고 가정한 경우에는
- forward language model은 t1, t2... t_(k-1)이 주어질 때, 다음 번째 token인 t_k를 예측하는 모델
- 각 k번째 token은 j번째(where 1.. N) LSTM Layer에서의 output은
- 그렇다면 마지막(최상단) LSTM layer의 출력 값(output)은
으로 표기할 수 있으며, 이 값은 softmax layer를 통해서 t_(k+1)을 예측하게 됨
따라서 forward LM의 최종 수식은
Backward LSTM
- forward layer와 유사하며, (t_(k+1), t_(k+2)... t_N) 번째 토큰이 주어지면, t_k번 째 Token을 예측하는 모델
- 각 k번째 token이 j번째(where 1,2... N) LSTM layer에서의 output 값은
- 마지막(최상단) LSTM layer 출력 값(output)은
- 으로 표기하며, 이 값은 softmax layer를 통해서 t_(k-1)을 예측하게 됨
따라서 backward LM의 최종 수식은
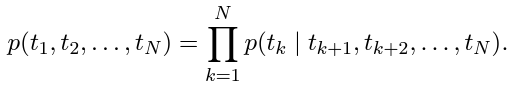
그래서 결국에 biLM은
- biLM은 forward LM과 backward LM을 결합(combine) 한 것
- biLM의 목표는
- forward, backward 두 방향 모두에 대해서 log likelihood를 극대화하는 것
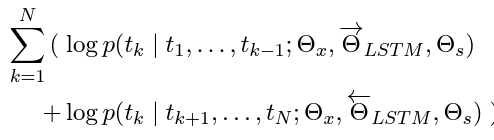
- 위 수식을 설명하자면
- forward, backward가 모두 공유하면서 사용하는 것은
- token representation (Θx)과 Softmax layer (Θs)에 대한 파라미터를 공유함
- forward, backward가 공유하지 않는 것은
- 각각 방향의 LSTM은 각자의 parameter값을 가짐
3.2 ELMo
- L개의 LSTM layer 사용하는 biLM이 특정 task에 대해서 학습이 된다면
- token t_k에 대해 생성되는 representations의 수는 2L+1개임
왜 2L+1개인 이유는 아래 수식
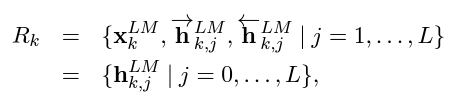
그래서 이 수식이 뭐냐고 묻는 다면
- 기존 단어의 임베딩 x_k^LM : 1개
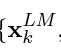
- forward, backward 모델의 L개의 layer에서 h(hidden_state) 값이 생성 : L개 +L개 =2L
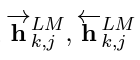
결론적으로
- 하나의 downtream task를 수행하려면 ELMo는 모든 layer에 대한 representation을 하나의 single vector로 합침
최종 수식은
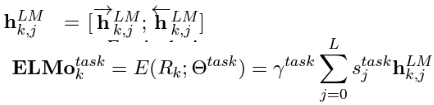
수식 설명을 하자면
- 특정 task에 대해서 k번째 token을 representation 하는 ELMo 방식은
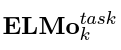
- 각각 forward, backward LSTM의 output 값인 각각의 h값에(j=0... L)
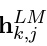
- 해당 task의 j번째 layer의 softmax-normalized weight값을 곱하고 각각의 h를 더함
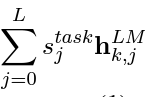
- 마지막으로 위 값에 scaler parameter(γ)를 곱함, γ는 optimization에서 중요한 역할을 함
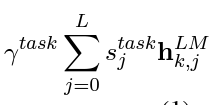
3.3 Using biLMs for supervised NLP tasks
- pre-trained biLM과 특정 task에 대한 a supervised architecture가 주어지면 biLM을 사용하는 것은 매우 간단하며 ELMo를 적용하는 것 또한 어려운 작업이 아님
ELMo를 추가하는 방법은
- supervised model에 ELMo를 추가하기 위해서는 표준 형식은 contex_independent token의 representation인 x_k에
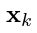
- ELMo vector를 concatenate(결합)해서 ELMo enhanced representation을 생성함
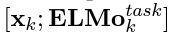
- 그리고 ELMo enhanced representation을 model의 input으로 사용하며, ELMo vector를 생성하기 위해 계산에 사용된 biLM의 layer의 weight값이 train에 반영되지 않도록 freeze(얼다)시킴
4. Evaluation
- Table.1 사진에서는 기존 모델에 단순히 ELMo를 추가함으로써 SOTA를 달성한 것을 보여줌
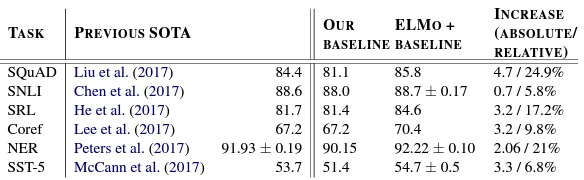
위 6개의 Tasks에 대한 간단한 설명
1. Question Answering
- 질의응답 문제를 해결하는 Task
- 데이터셋 : SQuAD(The Stanford Question Answering Dataset)
- 베이스라인 모델 : BiDAF
2. Texutal entailment
- hypothesis(가설)이 주어지면, premise(전제)가 True인지 False인지 결정하는 Task
- 데이터셋 : SNLI(The Stanford Natural Language Inference)
- 베이스라인 모델 : biLSTM
3. Semantic role labeling
- 자연어 문장의 서술어와 그 서술어에 속하는 논항들 사이의 의미 관계를 결정(의미역 결정)
- 베이스 라인 모델 : 8-layer deep biLSTM
4. Coreference resolution
- 실제 개체(entity)에 해당하는 임의의 개체(entitiy)를 언급/나타내는 다양한 mention(명사구)를 클러스터링 하는 Task
- 베이스라인 모델 : End-to-end Neural Coreference Resolution
5. Named entity extraction
- 이름이 가진 개체(named entity)를 인식하는 Task
- 즉, 어떤 이름을 의미하는 단어를 보고 그 단어가 어떤 type(유형)인지를 인식
6. Sentiment analysis
- 감성 분석 Task
- 베이스라인 모델 : BCN(biattentive classification network)
Conclusion
- 우리가 소개한 것은
- biLM을 사용해 높은 수준의 deep context-dependent representations를 위한 일반적인 접근법을 소개함
- 우리가 확인한 것은
- 대부분의 NLP Tasks에 ELMo를 적용했을 때 큰 성능 향상을 보여줬음
- biLM layers가 문맥(context) 내에 다양한 유형의 단어(word)를 효율적으로 인코딩한다고 확신하며 all layers를 사용하는 것은 전반적으로 task 수행 퍼포먼스를 향상하는 것을 확인함



