RoBERTa : A Robustly Optimized BERT Pretraining Approach
원문 : https://arxiv.org/abs/1907.11692
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperpar
arxiv.org
개요
이번 포스팅에서는 RoBERTa : A Robustly Optimized BERT Pretraining Approach 논문을 공부합니다.
나는 사용했다. 구글 번역기 번역을 위해서
Reference
twinjuy님의 oom해결을 위한 gradient accumulation
들어가기 전
Gradient accumulation
- step마다 gradient 업데이트하는 것이 아닌, 특정 배치 동안 계산된 gradient를 누적했다가 일정 이상 모이면 한 번에 업데이트하는 방식
TITLE : A Robustly Optimized BERT Pretraining Approach
Abstract
많은 매개변수와 데이터 사이즈 크기의 영향을 정밀하게 측정한 BERT replication study(재현 연구)를 진행함
연구후에 BERT가 underfit 되어 있는 것을 알 수 있었음.
이후에는 BERT 성능을 뛰어넘거나 그와 동일했고(RoBERTa) SOTA 달성함
요약 : BERT를 개선해서 성능 좋은 RoBERTa 가져옴
1. Introduction
- ELMo, GPT, BERT, XLM, XLNet 같은 self-training방식은 많은 성능을 향상했지만, 해당 방식에서 뭐가 큰 영향을 미친지는 결정하는 것은 어려울 수 있음
- 하이퍼 파라미터 튜닝 효과와 학습 데이터셋 크기의 effect에 대한 평가한 BERT pretraining의 복제 연구(replication study) 제안함
- 기존에 제시된 BERT가 underfit 되어서 성능이 매우 낮음을 발견했고 BERT와 성능이 일치하거나 더 좋은 RoBerta를 제시함
수정사항은 아래와 같음
- 더 길고 큰 배치 사이즈로 모델 학습
- NSP(Next Sentence Prediction) 제거
- 더 긴 Sequence로 학습
- 학습 데이터셋에 적용된 masking pattern을 dynamic 하게 변형
- 또한 새로운 데이터셋 CC-NEWS 사용
- GLUE와 SQuAD에서 SOTA 달성
요약 : CC-NEWS 사용하고 SOTA도 달성한 RoBERTa 제안함
2. Background
- BERT의 pretraing 접근법과 다음 섹션에서 보여 줄 학습 방법을 간략하게 보여줌
A. Setup
- BERT는 처음 unlabeled text courpus로 학습되며 labeld data로 fine-tune 됨
- 2개 문장을 결합해서 사용, 구분하기 위해 [SEP] 토큰 사용
B. Architecture
- BERT는 유비쿼터스 Transformer 아키텍처 사용 중
- L layer를 사용하며, 각 블록은 A 개의 self-attention heads와 hideen dimension H를 사용
C. Training Objectives
c.1 Masked Language Model(MLM)
- 입력 문장에서 임의의 토큰을 [MASK]로 대체함
- 먼저 입력 토큰의 15% 선택
- 15% 토큰 중 80%는 [MASK] 토큰으로 만듦
- 15% 토큰 중 10%는 unchanged 함
- 15 % 토큰 중 10%는 random 토큰으로 대체
c.2 Net Sentence Prediction(NSP)
- 두 문장이 관계가 있나 없나를 구분하는 이진 분류 방식
- 두 문장 이어지면 IsNect로 라벨링 하며 긍정
- 두 문장이 안 이어지면 NotNext로 라벨링 하며 부정
D. Optimization
- Adam
- 최대 문장길이 : 512 Token
- 미니 배치 크기 : 256
요약 : 간단한 BERT 설명
3. Experimental Setup
- BERT의 복제 연구(replication study)를 위한 실험 setup 설명
3.1 Implementaion
- 원래 BERT의 최적화 매개변수를 따라감
- 학습 속도와 warmup step은 변경함
- Adam의 epsilon값 튜닝하며, 큰 배치 사이즈에서는 β2=0.98 사용
- 최대 512 Token의 Sequence 사용하며, 무작위로 짧은 Sequence 사용 안 함
3.2 Data
- BERT에서 사용된 데이터셋 보다 크며, 양질의 데이터셋을 사용
- 데이터셋은 영어 포함 5개 domain이며, 160GB를 넘지 않음
아래는 데이터셋 특징들
- BERT 훈련 때 사용한 원본 데이터
- CommonCrawl News에서 영어 부분 (백만 건의 뉴스 기사)
- WebText-cor-pus의 open-source recreation(Reddit에서 공유된 URL에서 추출한 웹 콘텐츠)
- 데이터셋 STORIES
3.3 Evaluation
- pretrain model을 평가할 3가지 벤치 마크(GLUE, SQuAD, RACE)
4. Training Procedure Analysis
- 기존 BERT와 동일한 구성에서부터 시작함
4.1 Static vs Dynamic Masking
- 기존 BERT는 전처리 과정에서 한 번만 Masking 함. 이것을 Static Masking이라고 하며, 매 epoch마다 동일한 Masking data 학습했음
- 이것을 해결하기 위해 데이터를 10배로 복사해서 40 epoch 동안 10개의 다른 masking sequence를 학습함. 따라서 동일한 Masking Sequence를 총 4번밖에 학습하지 않음
- 아래 그림과 같이 Dynamic Masking은 Static Masking과 비슷하거나 좀 더 좋은 성능을 보여줌

요약 : Dynamic Masking 사용할 것임
4.2 Model Input Format and Next Sentence Prediction
- NSP는 두 개의 문장이 pair를 이루는지 확인하는 방식이며 기존 BERT의 성능에 좋은 영향을 가져옴
- 실제로 QNLI, MNLI에서 NSP를 제거하자 성능이 크게 저하되었음
- 하지만 최근 일부 연구에서는 NSP의 타당성이 제기되고 있고 본 논문에서도 타당성 실험을 위한 실험을 진행함
아래는 타당성 실험을 위한 학습 데이터셋 구성방식
1. SEGMENT-PAIR+NSP
- 기존 BERT에서 사용된 NSP와 동일한 설정, 각 pair 입력은 512 Token 미만
- NSP 사용
2. SENTENCE-PAIR+NSP
- 별도의 문서나 하나의 문서에서 샘플링된 자연스러운 Sequence를 입력으로 사용
- 하나의 입력은 대부분 512 Token보다는 작기 때문에 배치 사이즈를 늘려서 'SEGMENT-PAIR+NSP' 방식과 유사한 총 total tokens가 되도록 함
- NSP 사용
3. FULL-SENTENCES
- 각 입력값은 한 개 이상의 문서에서 연속적으로 샘플링된 full sentences이며, full sentences의 길이는 최대 512 Token
- 한 문서에서 샘플링이 끝나면 다음 문서에서 샘플링하여 full senteces를 채움
- NSP 사용 X
4. DOC-SENTENCES
- FULL-SENTENCE의 입력값과 구조가 비슷하지만, 하나의 문서에서 샘플링이 끝나면 다음 문서까지 샘플링하지 않음
- 따라서 끝부분에서 샘플링된 입력값은 512 Token 보다 작을 수 있어서, FULL-SENTENCE와 비슷한 Token을 얻기 위해 동적으로 배치 크기를 증가함
- NSP 사용 X
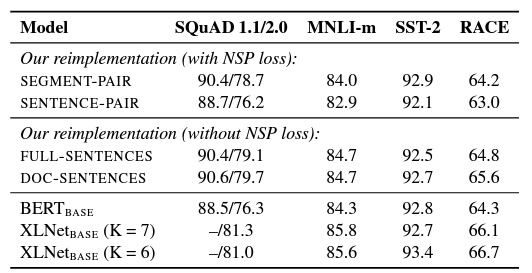
결과 해석
- 둘 다 NSP를 사용하는 SEGMENT-PAIR와 SENTENCE-PAIR(single sentence 사용)을 비교했을 때, 개별 sentences를 사용했을 때가 모델의 성능을 저하시킴. 이유는 모델이 learn long-range dependencies를 학습할 수 없기 때문임
- 그다음 NSP가 없는 DOC-SENTENCES를 사용함. 이것은 기존 BERT의 성능보다 좋고 NSP를 제거하는 것이 downstream tasks에 대한 성능을 약긴 향상하는 것을 발견함
- 하지만 DOC-SENTENCES는 배치 사이즈가 매번 달라지기 때문에 관련 Tasks들과의 비교를 위해 FULL-SENTENCES방식을 사용하겠음
요약 : DOC-SENTENCES가 성능이 젤 좋았지만, FULL-SENTENCES를 사용해 일관성 있게 다른 실험들과 비교
4.3 Training with large batches
BERT가 큰 배치 학습에 적합하다는 사실이 최근 연구에서 나옴
기존 BERT는 1m steps에서 256 batch size를 사용했는데 이것은 gradient accumulation을 사용했을 때,125 steps에서 batch size 2K와 31K steps에서 batch size 2K를 사용한 것과 동일한 계산 비용(computation cost)을 가짐
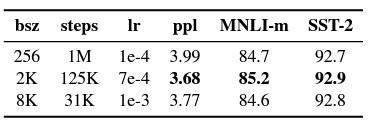
표에서 확인 가능하듯, Batch size를 증가시켜서 훈련하게 되면 성능이 향상된다는 것을 발견함
요약 : 배치 사이즈 늘려서 성능 향상 시킴
4.4 Text Encoding
- 기존 BERT는 character level BPE 방식을 사용했지만 RoBERTa는 Byte Level BPE를 사용함
- (GPT-2도 Byte Level BPE 사용)
요약 : Byte Level BPE 방식 사용
5. RoBERTa
해당 섹션에서 마치 모델의 아키텍처를 설명할 것 같지만, 그런 것은 아님
GLUE, SQuaD, RACE의 세 가지 벤치 마크 결과를 보여주며 논문의 저자들은 pretraining 단계에서 사용되는 데이터셋과 훈련 횟수에 에 대한 가중치를 둔 벤치 마크 결과를 보여줌
- 앞서 보여준 수정 사항으로 개선한 BERT인 RoBERTa를 제안함
- 즉, 기존 BERT에 Dynamic Masking, Full-SENTENCES without NSP, large mini-batches, byte level BPE방식을 사용해 학습하며 해당 모델의 이름은 RoBERTa
6. Related Work
NLP Taks에서 Pretraining 방식은 training단계에서 다양한 방법들에 대한 좋은 방법임
최근 연구에서는 pretraining 방식에 masking 방식을 사용하는 것을 도입하고 fine-tuning의 기본적인 방식을 사용함
그러나 더 새로운 방식으로 multi-task fine tuning방식에 entity embeddings, span prediction, auto-regressive의 변형을 결합한 방식이 더 좋은 성능을 내고 있음
또한 더 large 한 모델에 더 large 한 데이터셋을 학습하는 것도 성능 향상에 도움이 됨
우리는 이러한 상대적인 성능 향상 방식에 대해 더 잘이해하기 위해 BERT 복제 연구를 진행한 것임
7. Conclusion
- 우리는 BERT의 replication study를 통해 , (1) 더 많은 데이터에 대한 더 큰 배치 사이즈를 사용해 더 오래 학습, (2) NSP 삭제, (3) Dynamic Masking, (4) 더 긴 sequence로 학습을 함으로써 성능이 향상된 사실을 알아냄
- RoBERTa는 GLUE, RACE 및 SQuAD에서 SOTA를 달성함
- 또한 CC-NEWS라는 데이터셋을 사용함
- 코드도 공유함



