[구현] Transformer : Attention IS All YOU NEED
Reference
개요
Attention IS All YOU NEED 논문을 구현합니다.
순서
1. 논문 TEXT
2. 파란색 배경의 글자 : 논문 구현 코드
3. 주황색 배경의 글자 : 파란색 코드에 대한 보조 설명 코드, 없으면 생략
TITLE : Transformer : Attention IS All YOU NEED
Here, the encoder maps an input sequence of symbol representations (x1,..., xn) to a sequence of continuous representations z = (z1,..., zn)
1.Encoder(인코더)는 input sequence(x1 ~ xn)를 연속적인 임베딩 벡터 z=(z1... zn)로 변형함. 따라서 입력 문장을 토큰화
문장 X를 토큰으로 바꾸는 spacy 객체 선언 -토크 나이저, 품사 태깅 여러 기능 제공
import spacy
# 영어와 불어 spacy객체 선언
spacy_en = spacy.load('en')
spacy_de = spacy.load('de')
def tokenize_en(text):
return [token.text for token in spacy_en.tokenizer(text)]
def tokenize_de(text):
return [token.text for token in spacy_de.tokenizer(text)]spacy에서 제공하는 불용어 제거 메서드
text = 'Artificial intelligence has a lot to learn'
doc = spacy_en(text)
is_stop =[token.text for token in doc if not token.is_stop]
is_stop
#output
# 'a'가 사라짐
['Artificial', 'intelligence', 'lot', 'learn']2. 번역 모델에서 문장의 앞에 "<sos>", 뒤에는 "<eos>" 토큰을 넣는 것, 토큰을 소문자로 바꿔주는 것은 일반적인 작업
(논문에 나온 내용은 아님, Seq2Seq논문에서 나온 내용이며 또한 동빈나님의 강의에서 하신 말씀)
# transformer에서 입력을 넣을떄는 seq보다는 batch가 먼저오는 경우가 많음
SRC = Field(tokenize=tokenize_de, init_token = '<sos>', eos_token="<eos>",lower=True, batch_first=True)
TRG = Field(tokenize=tokenize_en, init_token = "<sos>", eos_token="<eos>",lower=True, batch_first=True)torchtext.data.Field?
- torchtext : NLP 분야에서 사용하는 DataLoader, v파일 Load, 토큰화, 인코딩, 단어 벡터화등의 작업 지원
Field 파라미터
- lower : 대문자 -> 소문자
- tokenize : 어떤 토큰화 함수 사용할 것 인지. string.split기본
- init_token/eos_token : 모든 문장/예제의 시작과 끝에 추가될 token
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs.
3. 논문에서는 WMT 데이터셋을 사용했고 총 450만 문장 pair를 사용했지만. 동일한 데이터셋을 사용하면 컴퓨터가 폭발하기 때문에 Multi30 k 데이터셋 사용
데이터셋 내려받고 단어 집합 생성
from torchtext.legacy.datasets import Multi30k
train_dataset, valid_dataset, test_dataset = Multi30k.splits(exts=(".de", ".en"), fields=(SRC, TRG))
print(f"train_Dataset size ; {len(train_dataset.examples)}")
print(f"valid_dataset size ; {len(valid_dataset.examples)}")
print(f"test_dataset size ; {len(test_dataset.examples)}")
# output
train_Dataset size ; 29000
valid_dataset size ; 1014
test_dataset size ; 1000Multi30k.splits 출력
- 데이터셋 내용 확인할 때는 examples 사용
- vocab.stoi(string to integer) 사용 시 단어와 매핑된 고유 정수 확인 가능
print(vars(train_dataset.examples[0])['src'])
print(vars(train_dataset.examples[0])['trg'])
# output
['zwei', 'junge', 'weiße', 'männer', 'sind', 'im', 'freien', 'in', 'der', 'nähe', 'vieler', 'büsche', '.']
['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']
# 최소 2번 이상 등장한 단어만을 가지고 단어 사전 생성
# 사전을 만드는 이유 : 독일어를 영어로 번역할때, 각각의 초기 input 차원을 알수있기떄문
SRC.build_vocab(train_dataset, min_freq=2)
TRG.build_vocab(train_dataset, min_freq=2)
print(f"SRC 사전 크기 {len(SRC.vocab)}")
print(f"TRG 사전 크기 {len(TRG.vocab)}")
# output
SRC 사전 크기 7855
TRG 사전 크기 5893
print(f"없는 단어 : {TRG.vocab.stoi['hi']}")
print(f"sos token integer :{TRG.vocab.stoi['<sos>']}")
print(f"eos token integer :{TRG.vocab.stoi['<eos>']}")
print(f"padding token : {TRG.pad_token}")
# output
없는 단어 : 0
sos token integer :2
eos token integer :3
padding token : <pad>한 문장에 포함된 단어가 연속적으로 입력되어야 하는 경우, 배치 하나당 포함된 문장들이 가지는 단어 개수가 유사하도록 만들면 좋음. 이를 위해 Bucketiterator 사용
BuckerIterator를 사용해서 traindataset을 batch단위로 생성하며, splits 메서드를 사용해 비슷한 길이를 갖는 데이터로 batch를 생성
BATCH_SIZE=128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu'
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_dataset, valid_dataset, test_dataset),
batch_size=BATCH_SIZE,
device=device
)결과 확인
- <sos> 토큰은 2, <eos> 토큰은 3, padding 토큰은 1로 변경
- 배치 사이즈는 128
- CPU 0 : 0번 GPU
print(train_iterator.batch_size)
# 128
for i in train_iterator:
print(i)
break
# output
[torchtext.legacy.data.batch.Batch of size 128 from MULTI30K]
[.src]:[torch.cuda.LongTensor of size 128x28 (GPU 0)]
[.trg]:[torch.cuda.LongTensor of size 128x26 (GPU 0)]
for i in train_iterator:
src_ = i.src
for s in src_[0]:
print(s)
break
# output
tensor(2, device='cuda:0')
tensor(5, device='cuda:0')
tensor(232, device='cuda:0')
tensor(229, device='cuda:0')
tensor(26, device='cuda:0')
tensor(38, device='cuda:0')
tensor(672, device='cuda:0')
tensor(4, device='cuda:0')
tensor(3, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')
tensor(1, device='cuda:0')Model Architecture
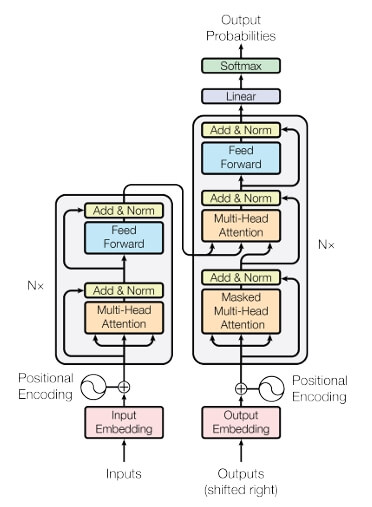
Encoder : The first is a multi-head self-attention mechanism
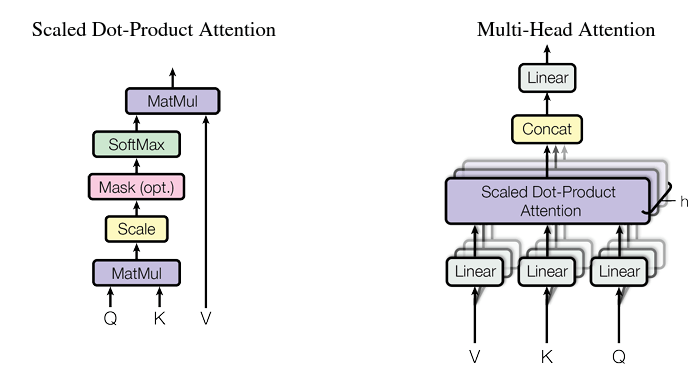
MultiHeadAttentionLayer
import torch.nn as nn
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, dropout_ratio, device):
super().__init__()
assert hidden_dim % n_heads == 0
self.hidden_dim = hidden_dim # 임베딩 차원
self.n_heads = n_heads # 헤드(head)의 개수: 서로 다른 어텐션(attention) 컨셉의 수
self.head_dim = hidden_dim // n_heads # 각 헤드(head)에서의 임베딩 차원
self.fc_q = nn.Linear(hidden_dim, hidden_dim) # Query 값에 적용될 FC 레이어
self.fc_k = nn.Linear(hidden_dim, hidden_dim) # Key 값에 적용될 FC 레이어
self.fc_v = nn.Linear(hidden_dim, hidden_dim) # Value 값에 적용될 FC 레이어
self.fc_o = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
# query: [batch_size, query_len, hidden_dim]
# key: [batch_size, key_len, hidden_dim]
# value: [batch_size, value_len, hidden_dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
# Q: [batch_size, query_len, hidden_dim]
# query_len : 단어 개수
# K: [batch_size, key_len, hidden_dim]
# V: [batch_size, value_len, hidden_dim]
# hidden_dim → n_heads X head_dim 형태로 변형
# n_heads(h)개의 서로 다른 어텐션(attention) 컨셉을 학습하도록 유도
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# Q: [batch_size, n_heads, query_len, head_dim]
# K: [batch_size, n_heads, key_len, head_dim]
# V: [batch_size, n_heads, value_len, head_dim]
# Attention Energy 계산
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# energy: [batch_size, n_heads, query_len, key_len]
# 마스크(mask)를 사용하는 경우
if mask is not None:
# 마스크(mask) 값이 0인 부분을 -1e10으로 채우기
# 이렇게하면 소프트맥스에 들어간 값이 거의 0%에 가까움
energy = energy.masked_fill(mask==0, -1e10)
# 어텐션(attention) 스코어 계산: 각 단어에 대한 확률 값
attention = torch.softmax(energy, dim=-1)
# attention: [batch_size, n_heads, query_len, key_len]
# 여기에서 Scaled Dot-Product Attention을 계산
x = torch.matmul(self.dropout(attention), V)
# x: [batch_size, n_heads, query_len, head_dim]
x = x.permute(0, 2, 1, 3).contiguous()
# x: [batch_size, query_len, n_heads, head_dim]
x = x.view(batch_size, -1, self.hidden_dim)
# x: [batch_size, query_len, hidden_dim]
x = self.fc_o(x)
# x: [batch_size, query_len, hidden_dim]
return x, attention1. def init
hidden_dim
- 하나의 단어에 대한 임베딩 차원
- n_heads = 헤드의 개수 = scaled Dot-Product Attention 수
head_dim
In this work we employ h = 8 parallel attention layers, or heads. For each of these we use dk = dv =dmodel/h = 64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
-
- = 각 헤드에서의 임베딩 차원
- = 하나의 단어를 n_head로 나눠서 사용하기 때문에 그때의 해당하는 차원
- = hidden_dim // n_heads
fc_q, fc_k, fc_v
- query, key, value에 적용될 fc 레이어(그림 참조)
fc_o
- 출력을 위한 output layer 왼쪽에 Scaled Dot-Product Attention
scale
The two most commonly used attention functions are additive attention [2], and dot-product attention.
Dot-product attention is identical to our algorithm, except for the scaling factor of 1 dk.
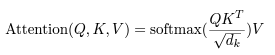
- 왼쪽에 있는 Scale
- 즉, 각 head_dim에 루트 씌운 값
2. def forward
Q, K, V.view
Instead of performing a single attention function with dmodel dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values.
- n_head만큼, 즉 Saled Dot-Product Attention 수만큼, 서로 다른 조합의 Q, K, V가 서로 다른 Head에서 Attention
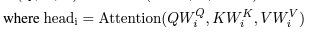
energy
- Attention 계산
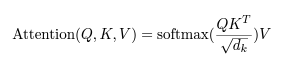
masked_fill
We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections
- mask 값이 0인 부분을 음의 무한대로 설정하게 되면, 소프트 맥스에서 확률 구할 때 값이 0%에 가까움
x.view(batch_size, -1, self.hidden_dim)
- concat 단계
.view() 예시
import torch
a = torch.range(1, 16)
a
# tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14.,15., 16.])
a = a.view(4, 4)
tensor([[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]])
a.view(1, -1)
tensor([[ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16.]])Position-wise-Feedforward
each of the layers in our encoder and decoder contains a fully connected feed forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between. The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality dff = 2048.
class PositionwiseFeedforwardLayer(nn.Module):
def __init__(self, hidden_dim, pf_dim, dropout_ratio):
super().__init__()
self.fc_1 = nn.Linear(hidden_dim, pf_dim)
self.fc_2 = nn.Linear(pf_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
def forward(self, x):
# x: [batch_size, seq_len, hidden_dim]
x = self.dropout(torch.relu(self.fc_1(x)))
# x: [batch_size, seq_len, pf_dim]
x = self.fc_2(x)
# x: [batch_size, seq_len, hidden_dim]
return x인코더와 디코더에 각각 Feedforward 레이어가 존재. 두 개의 선형 사이에서 RELU 연산을 하며, 입력과 출력의 차원이 동일하며 내부 레이어 차원이 2048로 존재함
hidden_dim : 단어에 대한 임베딩 차원
pf_dim : Feedforward 레이어 에서의 내부 임베딩 차원
Encoder Layer
- 한 개의 인코더레이어는 위 사진과 같이 4개의 레이어로 구성되어있음
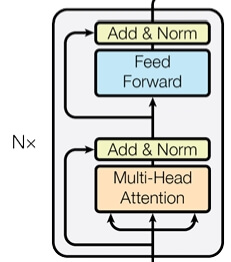
The encoder is composed of a stack of N = 6 identical layers.
인코더 레이어 6개로 구성했는데, 위 사진은 한개의 레이어의 구조임.
We employ a residual connection [11] around each of the two sub layers, followed by layer normalization [1]. That is, the output of each sublayer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself.
4개 레이어 중 2개는 위에서 구현한 Multi-Head Attention, Feed Forward layer이며, 나머지 two sub layers는 normalization layer임
따라서 init에서 LayerNorm를 입력 차원(hidden_dim)으로 초기화
class EncoderLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, pf_dim, dropout_ratio, device):
super().__init__()
# 4개의 레이어
self.self_attn_layer_norm = nn.LayerNorm(hidden_dim)
self.ff_layer_norm = nn.LayerNorm(hidden_dim)
self.self_attention = MultiHeadAttentionLayer(hidden_dim, n_heads, dropout_ratio, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hidden_dim, pf_dim, dropout_ratio)
self.dropout = nn.Dropout(dropout_ratio)
# 하나의 임베딩이 복제되어 Query, Key, Value로 입력되는 방식
def forward(self, src, src_mask):
# src: [batch_size, src_len, hidden_dim]
# src_mask: [batch_size, src_len]
# self attention
# 필요한 경우 마스크(mask) 행렬을 이용하여 어텐션(attention)할 단어를 조절 가능
# Query, Key, Value로 복제해서 넣음, 특정 단어에 대해서 attention을 수행하지 않기 위해 mask
_src, _ = self.self_attention(src, src, src, src_mask)
# dropout, residual connection and layer norm
src = self.self_attn_layer_norm(src + self.dropout(_src))
# src: [batch_size, src_len, hidden_dim]
# position-wise feedforward
_src = self.positionwise_feedforward(src)
# dropout, residual and layer norm
src = self.ff_layer_norm(src + self.dropout(_src))
# src: [batch_size, src_len, hidden_dim]
return src4개의 레이어를 초기화하고 그림과 같은 순서로 진행함
Encoder 아키텍처
위 코드는 1개의 인코더 레이어였음, 이제 N개 중첩해서 사용한다고 했으니 인코더 아키텍처를 생성
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, n_layers, n_heads, pf_dim, dropout_ratio, device, max_length=100):
super().__init__()
self.device = device
# input_dim(단어 갯수)에 해당하는 매트릭스가 들어왔을 때, 임베딩 차원(hidden_dim)으로 변경
self.tok_embedding = nn.Embedding(input_dim, hidden_dim)
# 논문과는 다르게 구현된 부분\
# 위치 임베딩(positional embedding)을 학습하는 형태
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
# Encoderlayer는 중첩되서 사용됨, n_layers 만큼 반복
self.layers = nn.ModuleList([EncoderLayer(hidden_dim, n_heads, pf_dim, dropout_ratio, device) for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([hidden_dim])).to(device)
def forward(self, src, src_mask):
# src: [batch_size, src_len]
# src_mask: [batch_size, src_len]
# batch_size = 문장의 개수
batch_size = src.shape[0]
# 문장중에서 단어가 가장많은 문장의 단어개수
src_len = src.shape[1]
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos: [batch_size, src_len]
# 소스 문장의 임베딩과 위치 임베딩을 더한 것을 사용
# 입력임베딩값에 위치에 대한 정보가 포함된(pos_embedding)데이터를 실제입력값으로 사용
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
# src: [batch_size, src_len, hidden_dim]
# 모든 인코더 레이어를 차례대로 거치면서 순전파(forward) 수행
for layer in self.layers:
src = layer(src, src_mask)
# src: [batch_size, src_len, hidden_dim]
return src # 마지막 레이어의 출력을 반환1. args
- input_dim : 단어 하나에 대한 원-핫 인코딩 차원
- hidden_dim : 단어 하나에 대한 임베딩 차원
- n_layers : 인코더 레이어 개수
- n_head : Head 개수 = Scaled dot-Product attention 개수
- pf_dim : Feedforward 레이어에서 내부 임베딩 차원
2. init
pos_embedding
in order for the model to make use of the order of the sequence, we must inject some information about the
relative or absolute position of the tokens in the sequence. we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed
문장에 대한 순서를 부여하기 위해서 우리는 positional encoding을 사용함
실제 코드에서는 sin, cos과 같은 연산을 하지 않고 위치 임베딩을 사용!
nn.ModuleList
nn.Module을 리스트로 정리, 리스트에 각 Layer를 담아 전달하면 레이어의 반복자(iterator)를 생성함. 이 때문에 forward 방식이 간편해짐. 여기서는 N개 중첩하는 Head Layer를 Iterator 하게 생성함
3. forward
batch_size : 문장 개수
src_len : 단어가 가장 많은 문장
결과적으로 src 반환(Decoder에서 써야지!)
Decoder Layer
- Decoder Layer를 N번 중첩해서 사용
- Encoder에서 사용된 레이어와 동일하며 Multi-Head Attention과 Norm Layer가 한 번씩 더 사용
- Encoder에서 반환받은 src값과 Decoder의 Q값을 을 사용하는 Multi-Head Attention
- Self-Attention과 Masking을 사용하는 Masked Multi-Head Attention이 있음
In "encoder decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence
- encoder-decoder attention layer에서는 Q는 Decoder에서, K, V는 Encoder의 output을 사용해서 입력 문장에 대한 위치 정보를 가질 수 있음

class DecoderLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, pf_dim, dropout_ratio, device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hidden_dim)
self.enc_attn_layer_norm = nn.LayerNorm(hidden_dim)
self.ff_layer_norm = nn.LayerNorm(hidden_dim)
self.self_attention = MultiHeadAttentionLayer(hidden_dim, n_heads, dropout_ratio, device)
self.encoder_attention = MultiHeadAttentionLayer(hidden_dim, n_heads, dropout_ratio, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hidden_dim, pf_dim, dropout_ratio)
self.dropout = nn.Dropout(dropout_ratio)
# 인코더의 출력 값(enc_src)을 어텐션(attention)하는 구조
def forward(self, trg, enc_src, trg_mask, src_mask):
# trg: [batch_size, trg_len, hidden_dim]
# enc_src: [batch_size, src_len, hidden_dim]
# trg_mask: [batch_size, trg_len]
# src_mask: [batch_size, src_len]
# self attention
# 자기 자신에 대하여 어텐션(attention)
_trg, _ = self.self_attention(trg, trg, trg, trg_mask)
# dropout, residual connection and layer norm
trg = self.self_attn_layer_norm(trg + self.dropout(_trg))
# trg: [batch_size, trg_len, hidden_dim]
# encoder attention
# 디코더의 쿼리(Query)를 이용해 인코더를 어텐션(attention)
_trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask)
# dropout, residual connection and layer norm
trg = self.enc_attn_layer_norm(trg + self.dropout(_trg))
# trg: [batch_size, trg_len, hidden_dim]
# positionwise feedforward
_trg = self.positionwise_feedforward(trg)
# dropout, residual and layer norm
trg = self.ff_layer_norm(trg + self.dropout(_trg))
# trg: [batch_size, trg_len, hidden_dim]
# attention: [batch_size, n_heads, trg_len, src_len]
return trg, attention1. init
- 사용되는 6개 레이어 초기화
2. forward
- self_attention : Q, K , V는 동일
- encoder_decoder attention : Q는 디코더에서, K, V는 인코더의 출력 값 사용
Decoder 아키텍처
- Decoder Layer를 N번 중첩해서 아키텍처 구성
- 인코더 아키텍처의 코드 구성과 동일하기 때문에 설명 생략
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, n_layers, n_heads, pf_dim, dropout_ratio, device, max_length=100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(output_dim, hidden_dim)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.layers = nn.ModuleList([DecoderLayer(hidden_dim, n_heads, pf_dim, dropout_ratio, device) for _ in range(n_layers)])
self.fc_out = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([hidden_dim])).to(device)
def forward(self, trg, enc_src, trg_mask, src_mask):
# trg: [batch_size, trg_len]
# enc_src: [batch_size, src_len, hidden_dim]
# trg_mask: [batch_size, trg_len]
# src_mask: [batch_size, src_len]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos: [batch_size, trg_len]
trg = self.dropout((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos))
# trg: [batch_size, trg_len, hidden_dim]
for layer in self.layers:
# 소스 마스크와 타겟 마스크 모두 사용
trg, attention = layer(trg, enc_src, trg_mask, src_mask)
# trg: [batch_size, trg_len, hidden_dim]
# attention: [batch_size, n_heads, trg_len, src_len]
output = self.fc_out(trg)
# output: [batch_size, trg_len, output_dim]
return output, attentionTransformer 아키텍쳐
- Encoder 아키텍쳐 + Decoder 아키텍쳐
- 입력 -> 인코더 -> 디코더 -> 출력
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_pad_idx, trg_pad_idx, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
# 소스 문장의 <pad> 토큰에 대하여 마스크(mask) 값을 0으로 설정
def make_src_mask(self, src):
# src: [batch_size, src_len]
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# src_mask: [batch_size, 1, 1, src_len]
return src_mask
# 타겟 문장에서 각 단어는 다음 단어가 무엇인지 알 수 없도록(이전 단어만 보도록) 만들기 위해 마스크를 사용
def make_trg_mask(self, trg):
# trg: [batch_size, trg_len]
trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(2)
# trg_pad_mask: [batch_size, 1, 1, trg_len]
trg_len = trg.shape[1]
trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), device = self.device)).bool()
# trg_sub_mask: [trg_len, trg_len]
trg_mask = trg_pad_mask & trg_sub_mask
# trg_mask: [batch_size, 1, trg_len, trg_len]
return trg_mask
def forward(self, src, trg):
# src: [batch_size, src_len]
# trg: [batch_size, trg_len]
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
# src_mask: [batch_size, 1, 1, src_len]
# trg_mask: [batch_size, 1, trg_len, trg_len]
enc_src = self.encoder(src, src_mask)
# enc_src: [batch_size, src_len, hidden_dim]
output, attention = self.decoder(trg, enc_src, trg_mask, src_mask)
# output: [batch_size, trg_len, output_dim]
# attention: [batch_size, n_heads, trg_len, src_len]
return output, attention1. make_src_mask
- 입력 문장의 <pad> 토큰에만 Masking
2. make_trg_mask
- 타깃 문장의 <pad> 토큰에 Masking
- 이전 단어만 확인할 수 있게 Masking
torch.trill
>>> a = torch.randn(3, 3)
>>> a
tensor([[-1.0813, -0.8619, 0.7105],
[ 0.0935, 0.1380, 2.2112],
[-0.3409, -0.9828, 0.0289]])
>>> torch.tril(a)
tensor([[-1.0813, 0.0000, 0.0000],
[ 0.0935, 0.1380, 0.0000],
[-0.3409, -0.9828, 0.0289]])



