[논문 구현] Sequence to Sequence Learning with Neural Networks
Reference
느낀 점
아키텍처 구현은 정말 어렵다.. 아직은 겨우 이해하는 수준. 혼자 하라고 하면 못함
개요
동빈나님의 모델 구현 영상과 논문을 따라가면서 구현해보기
순서
1. 논문 TEXT
2. 파란색 배경의 글자 : 논문 구현 코드
3. 주황색 배경의 글자 : 파란색 코드에 대한 보조 설명 코드, 없으면 생략
TITLE : Sequence to Sequence Learning with Neural Networks
The goal of the LSTM is to estimate the conditional probability p(y1,...,yT′|x1,...,xT) where (x1,...,xT) is an input sequence and y1,...,yT′ is its corresponding output sequence whose length T′ may differ from T.
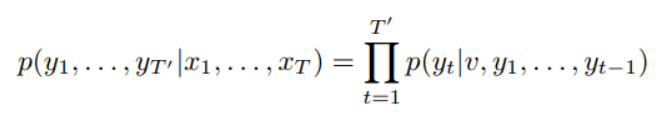
1. 문장을 토큰으로 바꾼다.
문장 X를 토큰으로 바꾸는 spacy 객체 선언 - 토크나이저, 품사 태깅 여러 기능 제공
import spacy
# 영어와 불어 spacy객체 선언
spacy_en = spacy.load('en')
spacy_de = spacy.load('de')spacy에서 제공하는 기본적인 기능
명사구, 동사, 토크나이저
text = 'Artificial intelligence has a lot to learn'
doc = spacy_en(text)
# 명사구 추출
print("Noun phrases:", [chunk.text for chunk in doc.noun_chunks])
# 동사 추출
print("Verbs:", [token.lemma_ for token in doc if token.pos_ == "VERB"])
Noun phrases: ['Artificial intelligence', 'a lot']
Verbs: ['have', 'learn']
# 토크 나이저
[(i,v) for i,v in enumerate(spacy_en.tokenizer(text))]
[(0, Artificial),
(1, intelligence),
(2, has),
(3, a),
(4, lot),
(5, to),
(6, learn)]we found it extremely valuable to reverse the order of the words of the input sentence. So for example, instead of mapping the sentence a,b,c to the sentence α,β,γ, the LSTM is asked to map c,b,a to α,β,γ, where α,β,γ is the translation of a,b,c
2. 문자열을 토큰으로 바꿨으면, 입력 때 순서를 뒤집어 줌
def tokenized_en(text):
return [t.text for t in spacy_en.tokenizer(text)]
print(tokenized_en(text))
# ['learn', 'to', 'lot', 'a', 'has', 'intelligence', 'Artificial']
def tokenized_de(text):
return [t.text for t in spacy_de.tokenizer(text)][::-1]Note that we require that each sentence ends with a special end-of sentence symbol “<EOS>”, which enables the model to define a distribution over sequences of all possible lengths. The overall scheme is outlined in figure 1, where the shown LSTM computes the representation of “A”, “B”, “C”, “<EOS>
3. 문장의 끝을 표시하는 <EOS> 토큰이 추가되어야 함. 즉, A, B, C토큰이 있다면, A, B, C <EOS>
필드 정의하기 (torchtext.data.Field)
SOS : Start of Sequence
EOS : End of Sequence
SRC = Field(tokenize=tokenize_de, init_token="<sos>", eos_token="<eos>", lower=True)
TRG = Field(tokenize=tokenize_en, init_token="<sos>", eos_token="<eos>", lower=True)torchtext.data.Field?
- torchtext : NLP 분야에서 사용하는 DataLoader, 파일 Load, 토큰화, 인코딩, 단어 벡터화 등의 작업 지원
Field 파라미터
- lower : 대문자 -> 소문자
- tokenize : 어떤 토큰화 함수 사용할 것인지. string.split 기본
- init_token/eos_token : 모든 문장/예제의 시작과 끝에 추가될 token, 없는 경우 None
We used the WMT'14 English to French dataset. We trained our models on a subset of 12M sentences consisting of 348M French words and 304M English words, which is a clean “selected” subset from
4. 논문에서는 WMT데이터셋을 사용했고 총 6억만 개의 단어를 사용해서 학습했지만, 내컴에서 하면 다운과 함께 컴퓨터가 폭발할 수 있음. Multi30 K 데이터셋 사용
데이터셋 내려받기고 단어 집합 생성
# Multi30k는 영어-독어 번역 데이터셋 3000만개의 데이터임
from torchtext.legacy.datasets import Multi30k
train_dataset, valid_dataset, test_dataset = Multi30k.splits(exts=(".de", ".en"), fields=(SRC, TRG))
# 영어, 독어 단어 생성, 최소 2번 이상 등장한 단어만 선택
SRC.build_vocab(train_dataset, min_freq=2)
TRG.build_vocab(train_dataset, min_freq=2)
Multi30k.splits 출력
- 불어(src ) 데이터, 즉 입력 문장은 순서가 뒤집어져서 들어간 것을 확인할 수 있음
- 데이터셋의 내용을 보고자 할 때는 examples 사용
- vocab.stoi를 사용하면 단어와 맵핑된 고유한 정수를 출력할 수 있음
- <sos> , <eos>는 정수 2, 3
print(vars(train_dataset.examples[1])['src'])
print(vars(train_dataset.examples[1])['trg'])
# outputs
# ['.', 'antriebsradsystem', 'ein', 'bedienen', 'schutzhelmen', 'mit', 'männer', 'mehrere']
# ['several', 'men', 'in', 'hard', 'hats', 'are', 'operating', 'a', 'giant', 'pulley', 'system', '.']
print(len(train_dataset))
print(len(valid_dataset))
print(len(test_dataset))
# 29000
# 1014
# 1000
print(TRG.vocab.stoi['<sos>'])
print(SRC.vocab.stoi['<eos>'])
print(TRG.vocab.stoi['dfafqf'])
# 2
# 3
# 0- vocab.stoi를 전체 확인해보면 5893개의 단어가 매핑되어 있음
print(len(TRG.vocab)) # 5893
TRG.vocab.stoi
we used a fixed vocabulary for both languages. We used 160,000of the most frequentwords for the source language and 80,000 of the most frequent words for the target language. Every out-of-vocabulary word was replaced with a special “UNK” token
5. 사전에 있는 단어만 사용하고 외래어는 {UNK} 토큰으로 대체했다
이것도 Field라이브러리라 다 해주더라..
한 문장에 포함된 단어가 연속적으로 LSTM에 입력되어야 하는 경우에, 배치 하나당 포함된 문장들이 가지는 단어의 개수가 유사하도록 만들면 좋다고 함. 이를 위해 Bucketiterator를 사용하며, 해당 내용은 논문에 적힌 것은 아니고 동빈 나 님의 영상 중에 나온 팁입니다.
BucketIterator를 사용해서 traindataset을 batch단위로 생성
BucketIterator.splits를 사용하면, 비슷한 길이를 갖는 데이터로 batch를 생성할 수 있음
BATCH_SIZE=128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu'
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_dataset, valid_dataset, test_dataset),
batch_size=BATCH_SIZE,
device=device
)첫 번째 배치만 확인
아래 결과는 128개의 배치에 있는 모든 문장은 34개의 토큰으로 구성될 수 있게 전 처리했음
# 배치단위로 확인해보기
for i, batch in enumerate(train_iterator):
src = batch.src
trg = batch.trg
print(f'batch.shape : {src.shape}')
for i in range(src.shape[0]):
print(f"idx {i} : {src[i][0].item()}")
break
# outputs
batch.shape : torch.Size([34, 128])
idx 0 : 2
idx 1 : 4
idx 2 : 0
idx 3 : 19
idx 4 : 7624
idx 5 : 16
idx 6 : 8
idx 7 : 3
idx 8 : 1
idx 9 : 1
idx 10 : 1
idx 11 : 1
idx 12 : 1
idx 13 : 1
idx 14 : 1
idx 15 : 1
idx 16 : 1
idx 17 : 1
idx 18 : 1
idx 19 : 1
idx 20 : 1
idx 21 : 1
idx 22 : 1
idx 23 : 1
idx 24 : 1
idx 25 : 1
idx 26 : 1
idx 27 : 1
idx 28 : 1
idx 29 : 1
idx 30 : 1
idx 31 : 1
idx 32 : 1
idx 33 : 1The simplest strategy for general sequence learning is to map the input sequence to a fixed-sized vector using one RNN, and then to map the vector to the target sequence with another RNN (this approach has also been taken by Cho et al. [5]). While it could work in principle since the RNN is provided with all the relevant information, it would be difficult to train the RNNs due to the resulting long term dependencies (figure 1) [14, 4, 16, 15]. However, the Long Short Term Memory (LSTM) [16] is known to learn problems with long range temporal dependencies, so an LSTM may succeed in this setting
시퀀스 학습 전략은 하나의 RNN 사용해 입력 문장을 고정 크기의 vector에 매핑 후, 그 벡터를 다른 RNN과 함께 Target 시퀀스에 매핑하는 것인데 RNN는 장기 종속성 문제가 있어서 LSTM이 해당 문제를 해결할 수 있을 것임
First, we used two different LSTMs: one for the input sequence and another for the output sequence, because doing so increases the number model parameters at negligible computational cost and makes it natural to train the LSTM on multiplelanguagepairs simultaneously[18] Second, we foundthat deep LSTMs significantly outperformedshallow LSTMs, so we chosean LSTMwith fourlayers
그래서 우리는 LSTM 2개를 사용했다. 한 개는 입력, 한개는 출력용. LSTM 4중으로 구현했음
그렇다면 입력 시퀀스를 고정 크기로 맞추는 Encoder, 고정 크기를 출력 시퀀스로 맞추는 Decoder가 필요함.
Encoder/Decoder는 LSTM layer 필요 , vocab 단어들을 원핫인코딩해서 사용해야 하니 embedding layer도 필요!!
사실 아키텍처 구현 부분은 아직은 이해보다 그냥 따라 하면서 익숙해지는 느낌
잘 모르지만 그냥 계속해보는 느낌.. 혼자 하라 하면 아직 못한다..
들어가기 전
import torch.nn as nn
embedding_layer = nn.Embedding(num_embeddings=len(vocab),
embedding_dim=2)- num_embeddings : 임베딩을 할 단어들의 개수, 다시 말해 단어 집합의 크기
- embedding_dim : 임베딩 할 벡터의 차원, 사용자가 정해주는 하이퍼 파라미터 -> 압축하려는 벡터의 임베딩 크기
Encoder
# 인코더(Encoder) 아키텍처 정의
class Encoder(nn.Module):
def __init__(self, input_dim, embed_dim, hidden_dim, n_layers, dropout_ratio):
super().__init__()
# 임베딩(embedding)은 원-핫 인코딩(one-hot encoding)을 특정 차원의 임베딩으로 매핑하는 레이어
self.embedding = nn.Embedding(input_dim, embed_dim)
# LSTM 레이어
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.rnn = nn.LSTM(embed_dim, hidden_dim, n_layers, dropout=dropout_ratio)
# 드롭아웃(dropout)
self.dropout = nn.Dropout(dropout_ratio)
# 인코더는 소스 문장을 입력으로 받아 문맥 벡터(context vector)를 반환
def forward(self, src):
# src: [단어 개수, 배치 크기]: 각 단어의 인덱스(index) 정보
embedded = self.dropout(self.embedding(src))
# embedded: [단어 개수, 배치 크기, 임베딩 차원]
outputs, (hidden, cell) = self.rnn(embedded)
# outputs: [단어 개수, 배치 크기, 히든 차원]: 현재 단어의 출력 정보
# hidden: [레이어 개수, 배치 크기, 히든 차원]: 현재까지의 모든 단어의 정보
# cell: [레이어 개수, 배치 크기, 히든 차원]: 현재까지의 모든 단어의 정보
# 문맥 벡터(context vector) 반환
return hidden, cellDecoder
Encoder에는 없던 fully connected layer가 추가됨
Seq2Seq 아키텍처에서는 하나의 input을 여러 번 호출해서 prediction값을 받음, 즉 forward 함수에서는 하나의 input을 받는 것을 반복
즉, 하나의 input에 대해서 -> 임베딩 -> 드롭아웃을 진행하고, 지금까지의 정보(hidden, cell)와 함께 LSTM에 넣어서 output값을 생성함. 이 output값을 fc_layer에 넣게 되어서 prediction이 발생
# 디코더(Decoder) 아키텍처 정의
class Decoder(nn.Module):
def __init__(self, output_dim, embed_dim, hidden_dim, n_layers, dropout_ratio):
super().__init__()
# 임베딩(embedding)은 원-핫 인코딩(one-hot encoding) 말고 특정 차원의 임베딩으로 매핑하는 레이어
self.embedding = nn.Embedding(output_dim, embed_dim)
# LSTM 레이어
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.rnn = nn.LSTM(embed_dim, hidden_dim, n_layers, dropout=dropout_ratio)
# FC 레이어 (인코더와 구조적으로 다른 부분)
self.output_dim = output_dim
self.fc_out = nn.Linear(hidden_dim, output_dim)
# 드롭아웃(dropout)
self.dropout = nn.Dropout(dropout_ratio)
# 디코더는 현재까지 출력된 문장에 대한 정보를 입력으로 받아 타겟 문장을 반환
def forward(self, input, hidden, cell):
# input: [배치 크기]: 단어의 개수는 항상 1개이도록 구현
# hidden: [레이어 개수, 배치 크기, 히든 차원]
# cell = context: [레이어 개수, 배치 크기, 히든 차원]
input = input.unsqueeze(0)
# input: [단어 개수 = 1, 배치 크기]
embedded = self.dropout(self.embedding(input))
# embedded: [단어 개수, 배치 크기, 임베딩 차원]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# output: [단어 개수 = 1, 배치 크기, 히든 차원]: 현재 단어의 출력 정보
# hidden: [레이어 개수, 배치 크기, 히든 차원]: 현재까지의 모든 단어의 정보
# cell: [레이어 개수, 배치 크기, 히든 차원]: 현재까지의 모든 단어의 정보
# 단어 개수는 어차피 1개이므로 차원 제거
prediction = self.fc_out(output.squeeze(0))
# prediction = [배치 크기, 출력 차원]
# (현재 출력 단어, 현재까지의 모든 단어의 정보, 현재까지의 모든 단어의 정보)
return prediction, hidden, cellSeq2Seq 아키텍처
- Encoder : Source sequence를 고정크기의 context vector로 인코딩
- Decoder : context vector를 타깃 문장으로 디코딩하는데 한 단어씩 넣어서 한 번씩 결과를 구하는 것을 반복
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
# encoder, decoder layer 초기화
self.encoder = encoder
self.decoder = decoder
self.device = device
# 학습할 때는 완전한 형태의 소스 문장, 타겟 문장, teacher_forcing_ratio를 넣기
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# Source sequence를 인코더에 넣어서 context_vector 생성
hidden, cell = self.encoder(src)
# 디코더(decoder)의 최종 결과를 담을 텐서 객체 만들기
# 디코더는 한번에 토큰하나만 넣기때문에 디코더는 여러번 돌아가야함
trg_len = trg.shape[0] # 단어 개수
batch_size = trg.shape[1] # 배치 크기
trg_vocab_size = self.decoder.output_dim # 출력 차원
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# 첫 번째 입력은 항상 <sos> 토큰
# 디코더에 넣는 input값에는 <sos>토큰 제외
input = trg[0, :]
# 타겟 단어의 개수만큼 반복하여 디코더에 포워딩(forwarding)
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output # FC를 거쳐서 나온 현재의 출력 단어 정보
top1 = output.argmax(1) # 가장 확률이 높은 단어의 인덱스 추출
# teacher_forcing_ratio: 학습할 때 실제 목표 출력(ground-truth)을 사용하는 비율
teacher_force = random.random() < teacher_forcing_ratio
input = trg[t] if teacher_force else top1 # 현재의 출력 결과를 다음 입력에서 넣기
return outputs
'논문' 카테고리의 다른 글
| [논문 구현] Transformer : Attention IS All YOU NEED (0) | 2022.08.20 |
|---|---|
| [논문 공부] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2022.08.08 |
| [논문 공부] GPT-1 :Improving Language Understanding by Generative Pre-Training (0) | 2022.07.31 |
| [논문 공부] Transformer : Attention IS All YOU NEED (0) | 2022.07.25 |
| [논문 공부] LSTM(Long Short-Term Memory)(feat. RNN) (0) | 2022.07.16 |



