BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
원문 : https://arxiv.org/pdf/1810.04805.pdf
개요
이번 포스팅에서 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문을 공부합니다.
나는 사용했다. 구글 번역기 번역을 위해서
Reference
https://facerain.club/bert-paper/
박지호 님의 BERT만 잘 써먹어도 최고가 될 수 있다?
들어가기 전
downstream task
- 해결하고자 하는 Task
Title : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Abstract
- 새로운 언어 representation 모델 BERT : Bidirectional Encoder Representations from Transformers를 소개함
- BERT은 unlabeled text을 가지고 deep bidirectional representations(깊은 양방향 표현)을 사전 학습함
- pre-trained 된 BERT는 모델 아키텍처 수정 안 하고 output_layer만 추가해서 다른 task에 전이 학습해서 사용음
- 11개 NLP분야에서 SOTA 달성함
요약 : 트랜스포머 기반 양방향 Encoder 모델 가지고 왔다
1. Introduction
자연어 처리 부분에서 사전 학습된 언어 모델을 사용하는 것이 효과적임
사전 학습된 언어 representations를 downstream task에 적용할 때는 'feature-based', 'fine-tuning' 두 가지 전략이 있음
1. 'feature_based' 방식(such as ELMo)
- 사전 학습된 representations을 추가적인 features로 사용하는 아키텍처
2. 'fine-tuning' 방식 (such as GPT-1)
- 특정 task에 대한 파라미터는 최소한으로 하여, downstream task을 위해 사용하려고 할 때 간단하게 모든 파라미터를 fine-tuning 해서 사용
- 즉, 최대한 범용적으로 학습시켜 fine-tuning 할 때 쉽게 하겠음
두 전략은 pre-traiing 중에 같은 objective function을 공유하며, 단방향 언어 모델(unidirectional language models)을 사용하여 일반적인 언어 표현을 학습함
현재 pre-trained representations에 관한 기술은 단방향 언어 모델이라 매우 제한적이고 양방향의 콘텍스트를 통합하는 것이 중요하다 생각함.
따라서 Transformers의 BERT: Bidirectional Encoder Representations를 제안하여 fine-tuning에 관한 접근법을 개선할 것임
단방향 접근법을 Masked language mode(MLM)으로 해결할 것임
MLM
입력 Sequence의 token에 Mask를 씌워서 masked 단어가 있는 context를 예측하는 방식
예시)
- "나는 국밥 먹었다" -> "나는 [Masked] 먹었다는 문장으로 변환
- "나는 [Masked] 먹었다"라는 문장에서는 "Masked"는 "국밥"이라고 예측
추가로 Next Sentence prediction(NSP)을 사용함
NSP
텍스트들이 pair 정보를 학습함
예시)
"나는 국밥을 먹었다" -> "국밥에 고기가 많았다" -> 참
"나는 국밥을 먹었다" -> "고기를 잡으러 갔다" -> 거짓
우리는 언어 모델에서 양방향으로 사전 학습하는 것이 얼마나 중요한지를 보여주고 NLP 11개 분야에서 SOTA를 달성해서 얼마나 좋은 지도 증명한다.
요약 : MLM, NSP를 사용한 트랜스 포머 기반 BERT 알고리즘 가져왔는데 매우 좋다
3. BERT
BERT 프레임워크에는 2단계(Pre-training, Fine-Tuning) 있음

pre-training
- unlabeled 데이터를 기반으로 학습
Fine-tuning
- BERT는 사전 학습된 파라미터로 먼저 초기화함
- 그다음, 모든 파라미터는 다시 downstream task에 대해서 labeled 데이터를 사용해서 fine-tuned
Model Architecture(모델 아키텍처)
- BERT 모델 아키텍처는 multi-layer bidirectional(양방향) Transformer encoder임
Denotion(표기 사항)
- L : 레이어 수(number of layers ==Transformer blocks)
- H : 히든 레이어 크기(hidden size)
- A : self-attention의 head 수(the number of self attention heads)
본 논문에서 2가지 모델에 대한 결과를 제안함
- BERT_BASE는 OPEN AI GPT와 비교를 하기 위해 모델 사이즈를 같게 함
- BERT_BASE : L=12, H=768, A=12, Total Parameters=110M
- BERT_LARGE : L=24, H=1024, A=16, Total Parameters=340M
Input/Output Representations
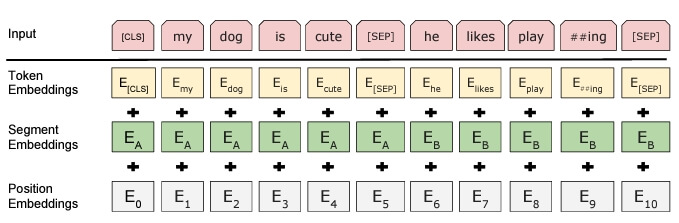
- 다양한 task를 다루기 위해서, 입력 representation을 single 혹은 한 쌍의 sequence들로 지정함
- 즉 , 하나의 Sequence token에는 한 문장 혹은 두 문장이 포함될 수 있다는 뜻
- 30000개의 토큰 어휘와 함께 WordPiece embeddings를 사용함
- <CLS> 토큰이 Sequence 토큰 맨 앞에 들어감, 분류 Task에서 사용
각 sentences를 구분하는 2가지 방법
- [SEP] 토큰 사용
- 문장 A 또는 문장 B에 속하는지 여부를 나타내는 모든 토큰에 학습된 임베딩을 추가
E : 위 방식으로 생성된 입력 임베딩(Figure 1에서 E 확인 가능)
토큰이 주어지면, BERT의 input representation은 token embeddings, segment embeddings, and position embeddings을 모두 더해서 만들어 짐(Figure 2)
3.1 Pre-Training BERT
LTR(left-to-right), RTL(right-to-left) 같은 방식을 사용해 BERT를 pre-train 하지 않음
2개의 unsupervised task를 이용해서 학습함(양방향 학습함) - (Figure 1 왼쪽 그림)
LTR 예시
"나는 국밥을 먹었다"라는 Sequence 가 있는 경우, 아래와 같은 토큰들을 학습함
"나는 - -"
"나는 국밥을 -"
Task #1: Masked LM
- 양방향 학습을 위해서 입력 토큰의 일부를 무작위로 Masked 처리하고 Masked 된 토큰을 예측함
본 논문에서 실험한 절차
fine-tuning 단계에서 [MASK]라는 토큰을 사용하지 않기 때문에 각 단계 사이의 mismatch를 유발함
mismatch 문제를 완화하기 위해 MASK로 선정된 것을 항상 [MASK]를 하지 않고 아래 절차를 수행함
- 모든 입력 토큰 중 15%를 마스킹하기로 함
- 15% 토큰 중 80%는 [Mask] 토큰으로 만듦
- 15% 토큰 중 10%는 unchanged 함
- 15% 토큰 중 10%는 random 토큰으로 대체함
Task #2: Next Sentence Prediction (NSP)
질의응답(Question & Answering)이나 자연어 추론(Natural Language Inference) 같은 downstream tasks들은 두 문장 사이의 관계(relationship)를 이해하는 것이 매우 중요함
따라서 각 문장의 관계를 이해하기 위해, BERT는 NSP task를 수행함
구체적인 과정
- 두 개의 Sequnece A, B로 구성함(2개 문장이지만, 하나의 입력으로 사용, [SEQ] 토큰으로 구분)
- 50%는 A의 다음 문장을 실제 문장인 B로 구성하며, "IsNext"라고 라벨링함 50%는 A의 다음 문장을 랜덤 하게 구성하며, "NotNext"라고 라벨링함
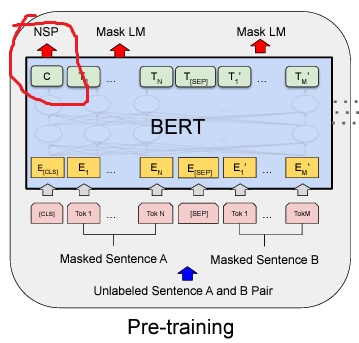
3. 출력 토큰 C를 사용해 NSP task 수행
Pre-training data
- BooksCorpus와 English Wikipedia을 pre-training dataset으로 사용함
3.2 Fine-tuning BERT
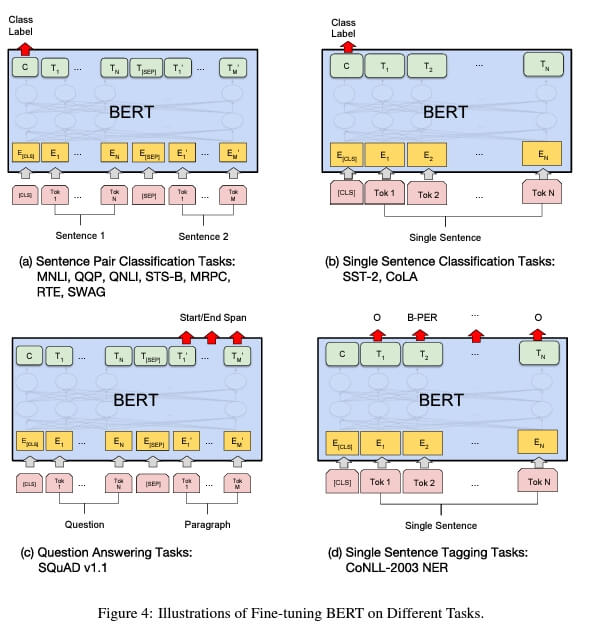
한 문장 또는 두 문장으로 이루어진 하나의 Sequence 입력을 모델의 입력으로 제공하기 때문에 downstream task에 Bert를 사용하는 것은 간단함. (두 문장인 경우는 하나의 Sequence로 입력받되, 두 문장끼리 self-attention)
각각의 Task에 맞게, 입/출력 데이터를 사용해 Bert모델의 모든 파라미터를 end-to-end 방식으로 fine-tune 함
Figure 4는 입력 Sequence별로 BERT를 적용하는 그림
(a) : 2개의 문장이 들어오는 경우 (such as QQP)
- QQP(Quora Question Pairs): Quora에 올라온 질문 Sequence pair가 동일한 의미를 가지는 확인하는 task
(b) : 한 개의 문장이 들어오는 경우 (such as SST-2)
- SST-2(Stanford Sentiment Treebank): 영화 리뷰에서 추출된 문장을 통한 긍정/부정 이진 분류 task
(c) : 질문과 본문이 들어오는 경우(such as SQuAD v1.1)
- 본문 속에서 질문에 대한 답을 예측
(d) : 문장 내 단어를 라벨링 하는 경우
- 품사 태깅
결론
- 언어 모델에서 전이 학습을 이용하는 것이 좋다고 많이 입증되어 왔고 unsupervised pre-training 방법은 필수적임
- 이 때문에 적은 resource를 사용해 성능 개선을 할 수 있음
- 우리의 연구가 도움이 될 것임
'논문' 카테고리의 다른 글
| [논문 공부] GPT-2 : Language Models are Unsupervised Multitask Learners (2) | 2022.08.27 |
|---|---|
| [논문 구현] Transformer : Attention IS All YOU NEED (0) | 2022.08.20 |
| [논문 구현] Sequence to Sequence Learning with Neural Networks (0) | 2022.08.02 |
| [논문 공부] GPT-1 :Improving Language Understanding by Generative Pre-Training (0) | 2022.07.31 |
| [논문 공부] Transformer : Attention IS All YOU NEED (0) | 2022.07.25 |



