[논문 공부] ALBERT : A Lite BERT for Self-supervised Learning of Language Representations
원문 : https://arxiv.org/abs/1909.11942
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations and longer training times. To
arxiv.org
개요
이번 포스팅에서는 ALBERT : A Lite Bert For Self-Supervised Learning Of Language Representation 논문을 공부합니다.
나는 사용했다. 구글 번역기 번역을 위해서
Reference
들어가기 전
GLEU
- 비선형 활성화 함수
TITLE : ALBERT - A Lite BERT for Self-supervised Learning of Language Representations
Abstract
Natural language representation의 성능을 향상한 것 중 하나는
- NLP 모델 크기(size)를 증가하는 것이 downstream task에 대한 성능(performance)을 향상시킴
하지만 모델 크기를 증가시키는 것은
- GPU/TPU의 제한적인 메모리와 훈련시간이 길어지는 문제점이 동반됨
이런 문제점을 해결하기 위해서
- 두 가지 parameter reduction 기술을 사용했고 이는 메모리 소비를 줄이고 BERT의 학습 속도를 증가시킴
또한 우리는
- 문장 간 일관성(inter-sentence coherence) 모델링에 집중하는 self-supervised loss를 사용해 여러 개의 문장 입력(multi-sentence inputs)에 관한 downstream tasks의 성능을 향상시킴
결론적으로 자랑을 하자면
- ALBERT는 BERT-Large보다 적은 파라미터를 사용해 GLUE, RACE, SQuAD에서 SOTA 달성함
1. Introudction
다른 훌륭한 NLP Tasks에 대한 성능 향상에 대한 연구에서 알 수 있는 것처럼
- 모델 사이즈가 큰, 즉 large 한 network는 SOTA 달성하는데 매우 중요한 역할을 함
Model Size 가 중요하긴 한데.., 그러면 더 좋은 NLP 모델을 얻기 위한 쉬운 방법이 더 large한 model을 만드는 것?
- 그럴 수 있긴 한데 어렵다. 왜냐하면 현재 SOTA 모델은 수백억 개의 파라미터가 있기 때문에, 제한적인 메모리 때문에 모델의 사이즈를 더 확장하는 데는 어려움
메모리가 제한적이니까 솔루션으로 메모리 관리 잘하고 병렬화 방식 사용하면 되는 거 아님?
- 맞음. 이 두 방법은 memory limitation문제를 해결할 수 있음. 하지만..
하지만?
- 모델의 parametres 수에 직접적으로 비례하는 Communication overhead는 해결하지 못함. 즉, Large models 있어서 많은 parameters 수에 비례하는 communication overhead는 분산 학습( distributed training)의 속도에 영향을 미침
따라서 우리는
- 앞선 문제를 모두 해결하는 BERT보다 적은 parameter를 사용하면서, 두 개의 parameter reduction techniques를 적용한 ALBERT를 소개함
첫 번째 Techniques
- factorized embedding parameterization 방법
- large vocabulary embedding matrix를 두개의 small matrices로 분리함.
- 해당 방법은 파라미터 수 증가 없이 hidden size를 늘릴 수 있음
두 번째 Techinques
- cross-layer paramert sharing 방법
- 해당 방법은 파라미터가 network depth에 비례하여 증가하는 문제를 해결함
이 두 방식을 적용한 ALBERT는
- BERT-Large 보다 파라미터가 18배 적고, 학습 속도가 1.7배 빠름
- 또한 두 방식은 regularization 방법으로 적용됨
추가적으로 ALBERT의 성능을 향상하기 위해서
- 문장 순서 예측(SOP : sentence-order prediction)을 위해서 self-supervised loss 적용함
- SOP loss는 inter-sentence coherence에 중점을 두며 기존 BERT에서 사용된 비효율적인 NSP를 해결함
TIP
기존 BERT에서 사용된 NSP Task가 효과적이지 않다는 연구결과는 "RoBERTa"에서도 증명됨
결론적으로 또 자랑을 하자면
- ALBERT는 BERT-Large보다 적은 파라미터를 사용하며 GLUE, SQuAD 그리고 RACE에서 SOTA를 달성함
2. Related Work
2.1 Scaling Up Representation Learning For Natural Language
모델의 크기가 커질수록 성능이 향상되지만
- 대형 모델들은 GPU/TPU 메모리 제한 측면에서 제약이 많고 최신 SOTA 모델들은 수십억이 넘는 파라미터를 가지고 있기 때문에 쉽게 메모리 한계에 도달할 수 있음
이를 해결하기 위해서 속도가 늦어지는 대신 메모리 소비가 줄어드는 방식을 사용한 연구들이 있었지만
- 우리의 parameter-reduction techiques는 메모리 소비를 줄이고 학습 속도를 높였음
2.2 Cross-Layer Parameter Sharing
Transformer 아키텍처에서도 layers를 거쳐서 매개변수들이 공유하는 idea가 탐구되었긴 했지만
- 표준 인코더-디코더에 집중된 학습방식에 더욱 초점이 맞춰져 있었음
하지만
- 다른 연구들에서 cross-layer parameter sharing방식을 사용했을 때 성능이 향상된 사실을 보여줌
2.3 Sentence Ordering Objectives
ALBERT가 사용하는 pretraining loss는
- 두 연속적인 Text 세그먼트의 순서를 예측하는데 기반함
ALBERT에서 사용된 loss와 유사한 방식으로
- sentence embeddings값이 두 개의 consecutive sentences 을 결정하기 위해 학습되는 방식이 있음(Jernite et al)
하지만 ALBERT loss는
- two consecutive sentences가 아니고 consecutive text에 기반함
기존 BERT에서 두 번째 문장이 pair 한 지 확인하는 NSP를 사용했지만
- 우리는 Sentence ordering이 더욱 중요하며 유용하다는 사실을 발견함
3. The Elements Of ALBERT
- ALBERT 아키텍처 설명과 기존 BERT와 비교함
3.1 Model Architecture Chocies
- ALBERT 아키텍처의 Backbone은
- GLEU를 사용하는 Transofomer Encoder를 사용하는 점에서 비슷함
논문에서는 BERT의 표기법(notation)을 따름. 무슨 말이냐면
- E : Vocabulary Embedding size
- L : The number of encoder layers
- H : The hidden size
그리고
- Feed-Forward와 Filter 크기 : 4H로 설정
- Attention Head의 수 : H/64로 설정
또한 ALBERT에서는 3가지 요소가 추가됨
- Factorized Embedding Parameterization
- Cross-layer parameter sharing
- Inter-Sentence Coherence Loss
Factorized Embedding Parameterization
BERT에서는 Embedding size E와 Hidden layer size H를 동일하게 설정하는데
- 이러한 방식은 Modeling과 아래와 같은 이유에서 최적이 아님
첫 번째 모델링 관점에서 이유로는
- WordPiece Embedding은 context-independent 한 representation을 학습하는데
- Hidden-Layer Embedding은 context-dependent representation을 학습함
근데 문장 길이, 즉 Context length에 관련된 실험을 보면
- Context-dependent representation이 모델 성능에서 강력한 역할을 수행함
따라서 Hidden layer 크기를 WordPiece Embedding 크기인 E보다
- 더 크게 하는 것이(H >>> E) 모델 성능 향상에 도움이 됨
하지만 H를 무조건 크게 할 수 없음. 왜냐하면
- NLP Task에서는 Vocabulary size, V를 크게 사용함.
- 만약 E=H인 경우, H를 증가시키면 Embedding matrix(V X E)가 같이 커지기 때문이며 매개변수가 매우 많은 모델이 생성될 것임
그래서 ALBERT는
- Embedding parameters를 두 개의 작은 matrix로 분해함
분해하는 방법은
- 원-핫 인코딩 된 V(Vocabulary Embedding vector)를 H(Hidden layer)에 바로 투영(V X H)하는 것이 아니라,
- 원-핫 인코딩 된 V를 더 낮은 차원의 WordPiece Embedding vecotr인, E에 먼저 투영(V X E) 시킨 후, Word Piece Embedding vector인 , E를 H(Hidden layer)에 투영(E X H) 시킴
결론적으로
- O(V X H) to O(V X E + E X H)으로 변환하여, Embedding parameters를 감소시켰고, 이것은 H 크기가 E보다 클 때 의미가 있음
Cross-layer Parameter Sharing
- parametyer 효율성을 증가시키기 위한 방법 중 하나임
먼저, Parameter Sharing을 위한 아래 방법들이 있음
- Sharing feed-forward networkd(FFN) parameters across layer
- Only sharing attention parameters
ALBERT는 2번째 방식에서 더 나아간
- Sharing all parameters across layers(레이어를 통한 모든 파라미터를 공유하는 방식)을 기본 설정으로 함
아래 그림은
- BERT-larget와 ALBERT-large의 각각의 Layer에서 입력/출력 임베딩의 L2 거리와 코사인 유사도를 보여줌.
- 또한 ALBERT-large에서 레이어와 레이어 사이에서 변환이 더욱 부드러운 것을 확인할 수 있음
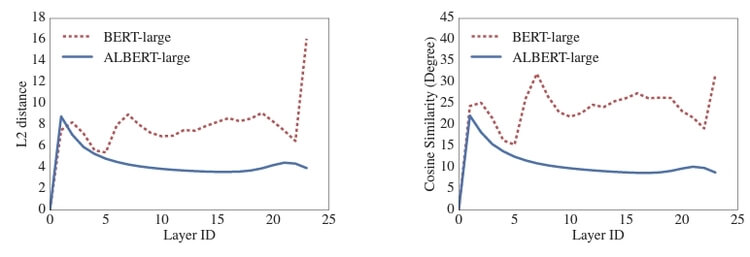
따라서 Sharing all parameters across layers 방식이
- Network parameter의 안전적인 변환에 영향을 미쳤다고 할 수 있음
Inter-sentence coherence loss
BERT는 MLM(masked language modeling) loss와 NSP (next-sentence prediction) loss를 사용했지만
- 후속 연구에 따르면 NSP Task가 신뢰할 수 없다고 판단했고 제거하기로 함
- 후속 연구 RoBERTa : RoBERTa 리뷰
우리가 NSP가 비효율적이라고 추측한 이유는
- NSP는 Topic prediction(주제 예측)과 Coherence prediction(일관성 예측)을 한 번에 동시에 수행하는데,
- Topic prediction이 Coherence prediction보다 더 쉽고, MLM도 Topic prediction을 위해 학습하기 때문에 겹치는 부분이 있음
우리는 언어이해의 관점에서 inter-sentence modeling 도 물론 중요하지만
- coherene(일관성)에 중점을 둔 Loss를 제안함
즉, ALBERT는 SOP(sentence-order prediction) loss을 사용함
- 이것은 Topic prediction은 수행하지 않고 inter-sentence coherence을 모델링하는데 중점을 둠
Inter-sentence coherence에 중점을 두기 위해서 SOP는 학습할 때 아래와 같은 segment를 사용함
- Positive examples : 두 문장의 순서가 올바름(BERT와 동일)
- Negative examples : 두 문장의 순서가 뒤바뀜
그리고 Sec 4.6에서 확인 가능 하지만, SOP는 NSP Task를 수행할 수 있지만
- NSP는 SOP Task를 수행할 수 없음
- 결과적으로
- ABLERT가 여러 downstream task에서 성능이 좋음
3.2 Model Setup

- BERT와 ALBERT의 파라미터를 비교한 표
- ALBERT-large는 BERT-larget보다 18배 적은 parameter를 가진 것처럼, ALBERT는 BERT보다 매우 적은 parameter를 사용함
4. Experimental Results
- BERT와 의미 있는 비교를 하기 위해, BERT의 Setup을 따름
Setup
- 16GB인 두 개의 말뭉치 데이터셋 BOOKCORPUS와 English Wikipedia을 pretrain에 사용
- 두개의 Segment인 입력의 경우, [CLS] x1 [SEP] x2 [SEP]의 입력 형식
- 최대 입력 길이는 512이며, 10% 확률로 512보다 짧게 변형
- Vocab size는 30000이며, SentencePiece를 사용해 토큰화
- MLM 타깃을 위해 n-gram masking 사용(n-gram의 최대길이는 3)
- 배치 사이즈는 4096
- LAMB optimizer with learning rate 0.00176
- 학습 step은 125000(특별한 경우를 제외)
5. Dicussion
ALBERT-xxlarge가 BERT-large 보다 parameter가 훨씬 적고 좋은 성능을 보여줬지만
- large-structure 때문에 계산 비용 더 비쌈
따라서 다음 목표는
- ALBERT의 train 및 inference속도를 높이는 것



