[논문 공부] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
원문 : https://arxiv.org/abs/1910.13461
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based
arxiv.org
개요
이번 포스팅에서는 BART: Denoising Sequence-to-Sequence Pretraining for Natural Language Generation, Translation, and Comprehension 논문을 공부합니다.
나는 사용했다. 번역을 위해서 구글 번역기
Reference
들어가기 전
perplexity
Chiara Campagnola의 Perplexity in NLP Model
TITLE : BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
1. Introduction
self-supervised 방식은
- NLP tasks에서 놀라운 성과를 냄
가장 성공적인 접근법은 MLM(Masked Language Model)인데, 이것은
- 특정 단어들을 masking & 복원(reconstruct)하도록 훈련된 denoising autoencoder임
최근 연구는 distribution of masked tokens을 개선해서 좋은 성과를 얻었지만,
- 이 방법은 특정 tasks에만 초점이 맞춰짐
우리는 Bidirectional Transformers와 Auto-Regressive Transformers을 결합한
- BART를 소개함
BART는 Seqence2Sequence 모델로 구축된
- denosing autoencoder 임
BART의 pretrain은 2단계로 이루어짐
- text는 임의의 nosing function에 의해 손상되고,
- sequence-to-sequence 모델이 text를 복원(reconstruct)하도록 훈련됨
BART는 기본적으로 Transformer 아키텍처를 따라감
앞에서 말한 setup들은 nosing이 flexibility하다는 장점이 있음
- 예를 들어 길이도 임의로 변환해서 원본 텍스트에 적용할 수 있음
우리는 여러개의 noising approaches를 평가함
- 원래 문장의 순서를 섞거나, 특정 길이 텍스트를 single mask token으로 대체하는 novel in-filling 기법 등 사용함
이러한 approaches 들은 BERT에서의 masking 단어와 NSP를 더 generalize 하기 떄문에
- 모델이 전체 문장길이에 대해 더 고려하며 다양하게 변형된 입력 문장에 대해 더욱 강력함
BART는 Text generation task에 굉장히 효율적이고
- 기계 독해 task에도 효율적임
BART는 RoBERTa와 GLUE와 SQuAD에서 동등한 성능을 보임
- 물론 학습 리소스 동일함
그리고 아래 분야에서 SOTA 달성함
- abstractive dialogue,
- question answering
- summarization tasks
또 BART는 fine-tuning에 대한 새로운 사고방식을 제시함
- 기계번역 task를 위해 BART모델에 추가적인 transformer layers를 더 쌓아 올림
- (뭐가 새로운 건데)
이 BART 루마니아어-영어 번역 task에서 좋은 성능을 냈고
- 관련 분석을 보여줌
아무튼 BART는
- 모든 범위의 task에서 강력함
2. Model
BART는 훼손된 문서(corrupted document)를 원래 문서(original document)로 복원하는
- Denoising autoencoder 임
BART는 훼손된 TEXT를
- Bidirectional Encoder로 인코딩 후
- LTR Autogressive Decoder를 사용하는
- Sequence-to-Sequence 구조를 가짐
또한 pre-training과정에서
- negativie log likelihood를 optimize 함
2.1 Architecture
BART는 Seq2Seq Transformer 구조이며
- 활성화 함수는 RELU를 변형한 GeLUs를 사용함
BART Base model은
- Encoder, Decoder가 각각 6개의 레이어로 구성되어있음
BART는 BERT의 아키텍처와 유사하지만,
- -BART는 각각의 Decoder Layer가 Encoder의 마지막 Hidden Layer와 cross-attention 수행(기존 Transformer Decoder와 동일)
- BERT는 word prediction 하기 전에 feeod-forward netword를 추가적으로 사용하지만 BART는 사용 안 함
이러한 이유로 BART 크기는
- 크기가 동일한 BERT보다 10% 많은 매개변수를 사용함
2.2 Pre-training BART
BART는 훼손된 문서를 복원하는 과정을 통해 loss를 최적화 시킴, 즉
- Decoder의 출력과 original document사이의 cross-entropy를 최적화시킴
BART는 모든 유형의 손상된 문서를 사용할 수 있음
- 특정 denoising autoencoders는 특정 체계 때문에 적용이 불가능한 경우가 있음
- 결론 : BART는 좋다
우리는 BART로 여러 실험을 했고
- 이러한 연구가 다른 연구의 기반이 될 거라고 생각함
Nosing 방법을 요약하자면 아래 그림임
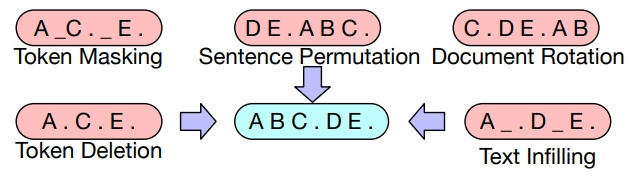
하나씩 설명하자면
Token Masking
- Token을 랜덤 하게 [MASK] 함(Like “BERT” 쿠엑)
Token Deletion
- Input에서 랜덤하게 Token을 삭제함. Masking과 다른 점은 삭제한 Token의 위치정보를 학습하는 것임
Text Infilling
- 여러 개 Text span이 선택됨(span 길이는 포아송 분포를 따름)
- 각 span은 하나의 [MASK] Token으로 대체함
- span 길이가 0이면 단순히 [MASK] Token이 삽입됨
- Text Infilling 방법은 SpanBERT에서 참고함.
- 다른 점은 SpanBERT는 Span 길이 정보를 알고 있어서 [Mask]된 Token의 개수를 알고 있음
- 하지만 Text Infilling은 Single MASK이기 때문에 몇 개의 단어가 [MASK]된 지를 맞춰야 함
Sentence Permutation
- Document를 sentence단위로 나누고, 랜덤 하게 shuffle 함
Document Rotation
- 랜덤으로 Token을 선택해서, 해당 Document(문서)가 해당 Token에서 시작하도록 함. 이는 Document의 시작점을 예측하기 위함
3. Fine-tuning BART
BART의 representation은 여러 Tasks들에 적용될 수 있고
- 몇몇의 Task에 따른 Fine-tuning 방식 소개함
3.1 Sequence Classification Tasks
인코더와 디코더에 동일한 Input값을 넣고
- Final decoder Token의 final hidden state를 multi-class linear classifier에 넣음
BERT의 [CLS] Token과 비슷하지만
- 추가 토큰을 끝에 추가하여 디코더의 토큰의 representation이 전체 Input에서 디코더 state에 참석함(뭔 소리냐 하면)
- 즉, 전체 input에 대한 Decoder의 attention을 계산하기 위해, Token을 추가함
3.2 Token Classification Tasks
완전한 문서(document)를 인코더와 디코더에 넣고
- 디코더의 top hidden state를 각 단어의 representation으로 사용, 이 representation은 Token Classification에 사용
3.3 Sequence Generation Tasks
BART가 autoregressive decoder를 가지고 있어서
- sequence generation tasks를 위해 사용할 수 있음
- sequence geneartion Task에는 abstractive question answering과 summarization 있음
이러한 tasks에서
- Input에서 정보가 복사되고 변형이 일어남(이것이 denoising pre-training 목적이기도 하니깐)
- 여기서 encoder의 입력으로는 input sequence이며
- decoder는 출력 값을 autoregressively 하게 생성함
3.4 Machine Translation
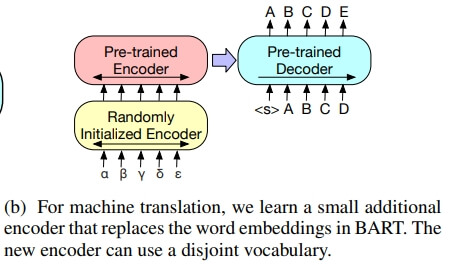
우리는 영어로 번역하는 기계번역 decoder를 개선하기 위해
- BART를 사용하는 방법도 찾아봄
일단 pre-trained encoder를 합쳐서 성능이 개선된다는 것을 보여준 이전의 연구가 있었지만
- pre-trained deocder를 사용하는 데는 한계가 있었음
하지만 우리는 보여줄게(Like "에일리" 쿠엑)
- 기계번역 Tasks를 위해 BART 모델 전체를 pre-trained decoder로서 사용하는걸
더 자세한 내용을 알려주면
- BART 인코더의 임베딩 레이어를 a new randomly initialized encoder로 교체했음
또 모델은 end-to-end로 학습되며
- new encoder는 번역 전 단어들을 매핑하며 학습하며, BART는 번역 후 단어(영어)로 denoise 함
- new encoder는 BART와 다른 vocab을 사용해도 됨
new encoder를 2단계로 구분해 학습하는데
- - 2단계 모두 BART의 output에 해당하는 cross-entropy loss를 사용해 backpropagation 함
첫 번째 단계에서는
- 대부분의 BART의 parameters를 업데이트하지 않고
- 아래 3개만 업데이트함
- randomly initialized source encoder
- BART positional embeddings
- self-attention input projection matrix of BART’s encoder first laye
두 번째 단계에서는
- iteration을 적게 하고 모델의 모든 parameters를 업데이트함
4. Comparing Pre-training Objectives
4.3 Results
아래는 우리가 실험한 실험 결과임
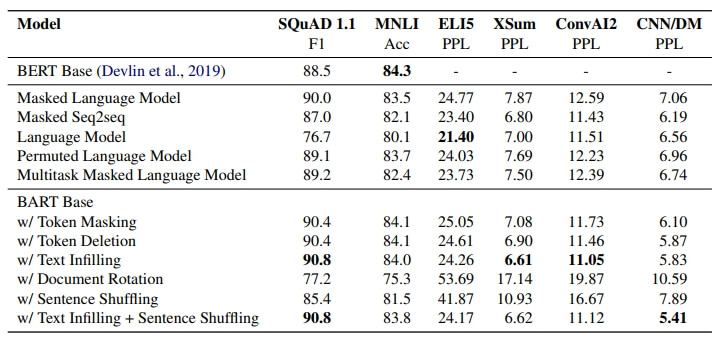
아래는 우리가 알아낸 사실임
1.pre-training 방식의 성능은 Tasks에 따라 다르다!
pre-training 방식의 효과는 Tasks에 따라 크게 달라짐. 예를 들면
- Simple Language Model은 ELI5에서 가장 좋은 성능을 보였지만, SQuAD에서 나쁜 성능을 보임
2. Token Masking은 중요해!
rotating documents이나 permuting sentences 방식을 단독으로 사용하면 성능이 별로 안 좋았고
- token deletion , masking, self-attention masks 사용하니까 성능 좋더라
- 특히, Token deletion 하는 경우 masking보다 성능이 더 좋더라
3. LTR(Letf-to-Right) Pre-training 방식은 Generation Tasks에서 좋은 성능을 냈어!
Masked Language Model과 Permuted Language Model은 Generation Tasks에서 안 좋은 성능을 보였는데,
- 이 두 개 모델만 LTR auto-regressive 모델링을 하지 않았음. 그러니까 합리적 주장이지?
4. Bidirectional encoders는 SQuAD에서 중요해!
LTR Decoder는 SQuAD에서 성능이 안 좋았음. 왜냐하면
- future context가 classification decision에 중요하기 때문임
- BART는 양방향 레이어 절반만 사용해서 비슷한 성능을 내긴 냈음
5. 꼭 pre-training 방법 말고도 다른 중요한 요소들이 많다!
Permuted Language Model은 XLNet 보다 성능이 안 좋았는데, 이유가
- relative-position embeddings이나 egment-level recurrence을 사용해서 아키텍처를 개선하지 않았기 때문이라고 생각함! 그러니까 pre-training 방법 말고도 중요한 게 많다는 말 인정?
6. Pure language models은 ELI5에서 BEST 달성했다!
ELI5 데이터 세트는 좀 달랐어. 무슨 말이냐면
- generation task들 중에 유일하게 BART가 아닌 다른 Pure Language model이 더 좋은 성능을 냈어
- 우리 생각에는 input-ouput의 연관성이 다소 낮아서(loosely constrained) 그랬다고 생각해
7. 하지만 역시 BART가 일관되게 강력한 성능을 냈지!
- text-infilling 기법을 사용한 BART가 몇 개의 task를 제외하고는 최고였다!
8. Conclusion
손상된 document를 original document로 복구하는 pre-training 방식인
- BART를 소개했음
BART는 discriminative task에서 RoBERTa와 유사한 성능을 냈고
- text generation tasks에서는 SOTA 달성함
향후 연구는
- document를 손상시킬 새로운 방법들을 찾아야 함



