MemInsight: Autonomous Memory Augmentation for LLM Agents
Large language model (LLM) agents have evolved to intelligently process information, make decisions, and interact with users or tools. A key capability is the integration of long-term memory capabilities, enabling these agents to draw upon historical inter
arxiv.org
LLM 에이전트는
- 단순히 질문에 답하는 걸 넘어서, 의사 결정 내리고, 사용자나 도구와 상호 작용하도록 발전해왔다
이런 에이전트의 핵심은 메모리에 있다
- 과거 대화를 저장해서 일관성 있고, 개인화된 응답을 생성 가능함
하지만 이런 메모리 구조에는 몇 가지 문제점이 있다고 함
- 데이터가 누적될수록 관련 정보 찾기 어려움
- 과거대화양이 많아져서 메모리 관리 어려움
- Raw 형식 저장은 불필요한 정보도 함께 저장되며, 이는 검색 품질 저하를 초래함
- 작업 간 지식 통합이 어렵다, 이는 다양한 문맥에서 정보 활용에 제약이 있음
그래서 이 문제를 해결하기 위해 MemInsight를 제안
To address these challenges, we propose
MemInsight, an autonomous memory augmentation approach that allows LLM agents to structure and utilize memory more effectively.
- LLM이 스스로 자신의 기억을 구조화하고 활용하게 만드는 방법
MemInsight에는 3가지 주요 구성 요소로 구성됨
- 속성 추출 (Attribute Mining)
→ 대화에서 중요한 속성 자동 추출 (ex: 감정, 주제, 의도) - 메모리 주석 (Memory Annotation)
→ 추출한 속성을 메모리에 정리하여 저장 - 기억 검색 (Memory Retrieval)
→ 나중에 필요할 때, 속성을 기준으로 관련 기억을 검색
Autonomous Memory Augmentation (자율 메모리 증강)
- 챕터 3, MemInsight를 설명하는 핵심 파트, 부록 B와 같이 봐야 함
MemInsight 구성요소 3단계 (이 세 과정이 "증강 -> 저장 -> 검색"의 흐름을 만듦)

- 속성 추출(Attribute Mining) : 의미 있는 속성 추출
- 메모리 주석(Annotation) : 속성으로 메모리에 주석을 다는 작업
- 검색(Memory Retrieval) : 속성을 이용해 적절한 기억 검색
그럼 속성(attribute)을 어떻게 정의하고 생성(추출) 할 건지? 가 궁금하다.
먼저, Effective 한 속성 = (meaningful + accurate + contextually relevant)이라고 함
그래서 속성 생성 시, 3가지 고려요소가 있음
- 속성 관점(Perspective)
- 속성 세부 수준 (Granularity)
- 속성 우선순위 (Prioritization)
첫 번째, Attribute Perspective
- MemInsight는 크게 2가지 관점을 사용함
- Entity-centric Perspective (객체 중심 관점) : 특정한 "항목(엔티티)"에 집중한 속성 생성 방식
- 영화 -> 감독, 배우, 장르, 개봉 연도
- 책 -> 작가, 출판사, 페이지 수, 시리즈 여부
- 예: [genre]<드라마>, [director]<봉준호>, [release_year]<2019>
- 영화 추천 시스템에서 개별 영화 정보 저장
- Conversation-centric Perspective (대화 중심 관점) : 전체 대화 흐름, 사용자 표현 등을 기반으로 속성 추출
- 사용자가 어떤 영화를 좋아하는 이유
- 감정 변화, 행동 동기, 선택 이유
- 예: [emotion]<기대됨>, [intent]<휴식 필요>, [preference]<가족 영화 선호>
두 번째, Attribute Granularity : 속성 세부 수준
- MemInsight는 크게 2가지 수준을 사용함
- Turn-level
- 개별 발화 기준으로 속성 추출(미세 분석)
- 더 세밀하고 정교한 정보 가능
- 예: “그 영화 감동적이었어.” → [emotion]<감동>
- Session-level
- 대화 전체를 요약해서 생성 (전반적 흐름 파악)
- 예: [topic]<가족 영화>, [overall_emotion]<힐링>
예시 대화
Melanie: "Caroline, 우리 마지막으로 얘기한 이후로 많은 일이 있었어. 지난 토요일에 정신 건강을 위한 자선 마라톤에 참가했거든. 정말 보람 있었어. 우리 마음도 잘 돌봐야겠다는 생각이 들었어."
Caroline: "와, 멜! 그 자선 마라톤 정말 멋지다! 정신 건강에 대한 인식을 높이는 건 정말 가치 있는 일이야. 너 정말 자랑스러워!"
Melanie: "고마워, Caroline! 요즘 자기 돌봄(self-care)이 얼마나 중요한지 느끼고 있어. 내가 나 자신을 잘 챙겨야 가족도 잘 챙길 수 있다는 걸 알게 됐어."
Caroline: "정말 공감해. 자기 자신을 돌보는 건 정말 중요하지. 항상 쉽진 않지만 꼭 필요한 일이야."
1. 이때, Turn-level Annotation (턴별 주석 예시)
Turn 1:
[event]: <정신 건강을 위한 자선 마라톤>
[time]: <지난 토요일>
[emotion]: <보람 있음>
[topic]: <정신 건강>
2. 그리고, Session-level Annotation (세션 전체 주석 예시)
Melanie:
[event]: <정신 건강 자선 마라톤 참가>
[emotion]: <보람 있음>
[intent]: <자기 돌봄에 대한 생각>
Caroline:
[event]: <정신 건강 인식 향상>
[emotion]: <자랑스러움>
이때, 부록에 보면 속성 생성은 zero-shot 방식 프롬프팅(예시)을 보여줌
# prompt
"You are an assistant that extracts key attributes from user utterances.
Input: “I had a rough day at work. Thinking of rewatching Spirited Away. It always helps me calm down.”
Output format:
[event]: <value>
[emotion]: <value>
[intent]: <value>
[movie]: <value>
===========================
생성 예시
[event]: rough day at work
[emotion]: stressed
[intent]: calming down
[movie]: Spirited Away마지막, Attribute Prioritization : 속성 우선순위 정렬
- 속성과 값을 메모리에 저장할 때 어떤 방식으로 저장할지를 다룸.
- 앞에서 속성을 뽑아냈으니, 이제 어떻게 저장? 을 정해야 함
저장 포맷
{mi: ⟨a1, v1⟩, ⟨a2, v2⟩, ..., ⟨an, vn⟩}
mi: 메모리 인스턴스 (하나의 대화 턴 혹은 세션)
ai: 속성 (attribute)
vi: 속성 값 (value)
ex)
Memory ID: conv_001
{
[event]<인사이드 아웃 2 감상>,
[emotion]<감동, 힐링>,
[intent]<감정을 치유하고 공유하고 싶음>,
[relationship]<가족과의 시간>,
[aspect]<감정 표현>,
[reaction]<눈물>,
[companion]<엄마>
}
속성 우선순위 방식 2가지
- Basic Augmentation
- 무작위 저장
- Priority Augmentation
- 중요도 기준으로 정렬
- 중요도 기준에 대해 자세히 나오지는 않음, 해당 메모리(예: 대화)와 더 밀접하게 관련된 속성부터 우선적으로 정렬이라고 명시되어 있음
그럼 Attribute Mining and Annotation (속성 생성 및 주석 달기)를 위한
3가지 단계를 좀 정리해 보자
- Attribute Perspective (관점 결정)
- 속성을 어떤 관점에서 추출할래? (영화? 대화?)
- Attribute Granularity (속성 수준 결정)
- 속성을 어느 수준으로 추출할래?, 어디까지 세밀하게 볼래? (한 문장? 전체 대화?)
- Annotation and Attribute Prioritization
- 속성을 어떻게 정렬하고 저장할래?
예시 대화, 3 턴
[Turn 1]
유진: 지난 주말에 엄마랑 '인사이드 아웃 2'를 봤어. 진짜 감동적이더라.
[Turn 2]
수연: 와, 그 영화 엄청 기대하고 있었는데! 어떤 점이 제일 좋았어?
[Turn 3]
유진: 캐릭터들이 감정을 표현하는 방식이 너무 좋았어. 눈물도 났고... 진짜 힐링됐어.
1. Attribute Perspective (속성 관점 선택)
Conversation-centric 선택 : 사용자(유진)의 감정, 경험, 의도, 선호를 중심으로 속성 추출
2. Attribute Granularity (속성 세부 수준 결정)
Turn-level (각 발화에서 직접 추출)
[Turn 1]
[event]: <영화 관람>
[companion]: <엄마>
[movie]: <인사이드 아웃 2>
[emotion]: <감동>
[Turn 3]
[aspect]: <감정 표현>
[reaction]: <눈물>
[emotion]: <힐링됨>
Session-level (전체 흐름 요약)
[event]: <인사이드 아웃 2 감상>
[emotion]: <감동 + 힐링>
[intent]: <감정을 치유하고 공유하고 싶음>
[relationship]: <가족과의 시간>
3. Annotation and Attribute Prioritization
Priority Augmentation 적용, 더 중요한 속성부터 정렬
1. [intent]<감정을 치유하고 공유하고 싶음>
2. [event]<인사이드 아웃 2 감상>
3. [emotion]<감동, 힐링>
4. [relationship]<가족과의 시간>
5. [aspect]<감정 표현>
6. [reaction]<눈물>
7. [companion]<엄마>다시 MemInsight 구성유소 3가지를 보면, 위에서 Mining과 Annotation을 알아봤음.
- 속성 추출 (Attribute Mining)
→ 대화에서 중요한 속성 자동 추출 (ex: 감정, 주제, 의도) - 메모리 주석 (Memory Annotation)
→ 추출한 속성을 메모리에 정리하여 저장 - 기억 검색 (Memory Retrieval)
그러면, Memory Retrieval (메모리 검색)에 대해 알아보자
- 속성을 사용한 메모리를 활용해 적절한 메모리를 검색하는 단계
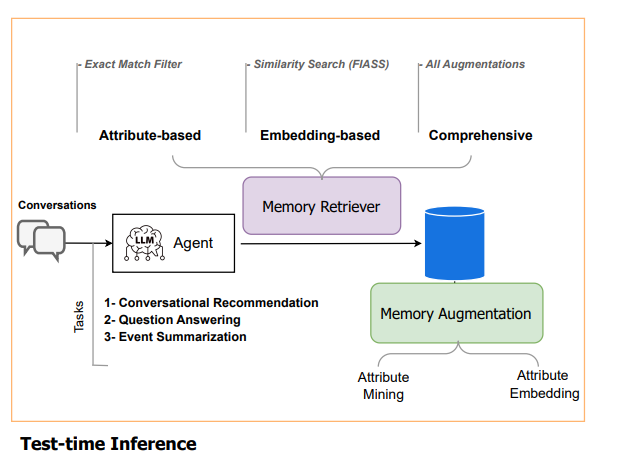
두 가지 검색 방식 + 두 방식을 모두 사용하는 방법(Comprehensive)
- Attribute-based Retrieval
- 현재 문맥에서 속성을 생성하고, 메모리에 있는 속성과 정확히 일치하는 데이터를 검색
- 예를 들어 현재 질문이 [genre]<드라마>와 [emotion]<감동>이라면
메모리에 이 두 속성을 가진 항목만 추출 - 장점 : 정확한 콘텍스트 일치, 사람이 직관적으로 이해하기 쉬움
- 단점 : 속성이 누락되거나 조금만 달라도 검색 X -> 유연성 떨어짐
- Embedding-based Retrieval
- 속성 전체를 임베딩하여 벡터 공간에서 유사한 메모리를 찾음
- 예: [emotion]<감동> [genre]<가족> → 문장으로 만들고 벡터화
- FAISS를 이용한 top-k 검색
- 검색된 메모리는 현재 대화에 통합되어 응답 품질을 향상
- 장점 : 유연성 높음
- 단점 : 사람이 해석하기에는 어려움
Embedding-based Retrieval에서 속성을 문장처럼 합쳐서 벡터로 변환한다고 함, 아래는 예시
[emotion]<감동> [event]<마라톤> [intent]<자기돌봄>
→ 임베딩 벡터로 변환실험 결과
1. 질문 응답 Task에서 각 모델의 F1 Score 비교 결과
- MemInsight는 전체적으로 가장 안정적이고 높은 성능을 보임
- Claude + Priority + 임베딩 조합이 가장 효과적
- RAG Baseline (DPR) : Dense Passage Retrieval로 문맥 검색 후 답변 생성
- 전반적으로 낮은 성능이지만, Adversarial 질문에서 최고 성능(89.9%) 기록
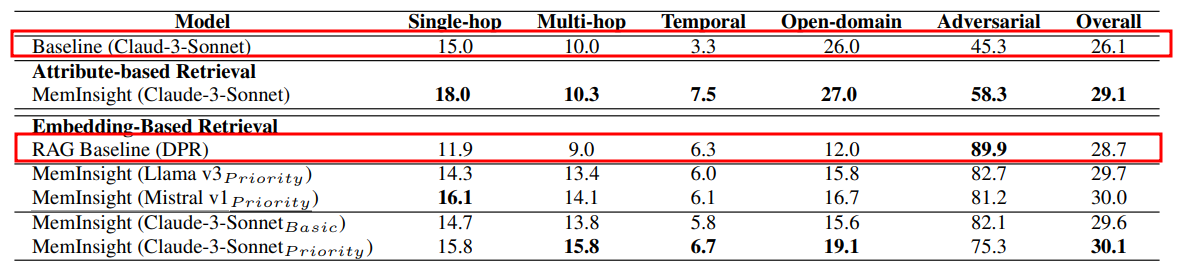
2. Memory Retrieval Accuracy (Recall@5) in 질문 응답 Task
- “과거 대화 중 어떤 문장이 이 질문과 관련 있는지 찾아야 하지?”
- 검색된 상위 5개의 기억 중에 정답이 포함되어 있으면 OK

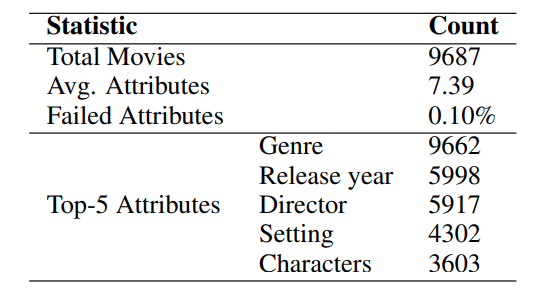
3. Statistics of attributes generated for the LLM - REDIAL
REDIAL 데이터셋 내에서 MemInsight가 메모리를 생성한
- 총 영화 개수 : 9687편
- 평균적으로 7.39개 속성 생성
- 속성 생성 실패율이 0.1%, zero-shot prompting으로도 실패 없이 잘 생성했다는 뜻
- 속성 주석 중 가장 많이 등장한 5개 속성, 장르 / 개봉 연도 / 감독 배경 / 주요 인물
단순히 추천 성능이 좋아졌다는 뜻이 아님
- 그 추천의 기반이 되는 메모리(영화 정보)가 얼마나 잘 구성되어 있는지를 보여주기 위한 표
- 이 표에는 직접적인 품질 점수는 없지만, 속성 수 / 실패율, 생성된 속성의 종류가 곧 "메모리 품질" 간접 지표다라는 걸 보여주고 있음
4. 설득력(Persuasiveness) & 관련성(Relatedness) 평가
- 영화 추천이 인간 관점에서 납득이 가는지, 자연스러운지 평가한 결과
- recall 지표가 "맞췄냐?"를 본다면, 여기선 "말이 되냐?"를 봄
- 근데 인간 관점에서 평가를 인간이 아닌 LLM이 대신한 평가 결과
결과
- Claude-Haiku 기반 임베딩 검색이 가장 설득력 있는 추천을 생성
- Mistral 기반 모델은 정답과 가장 유사한 추천을 수행
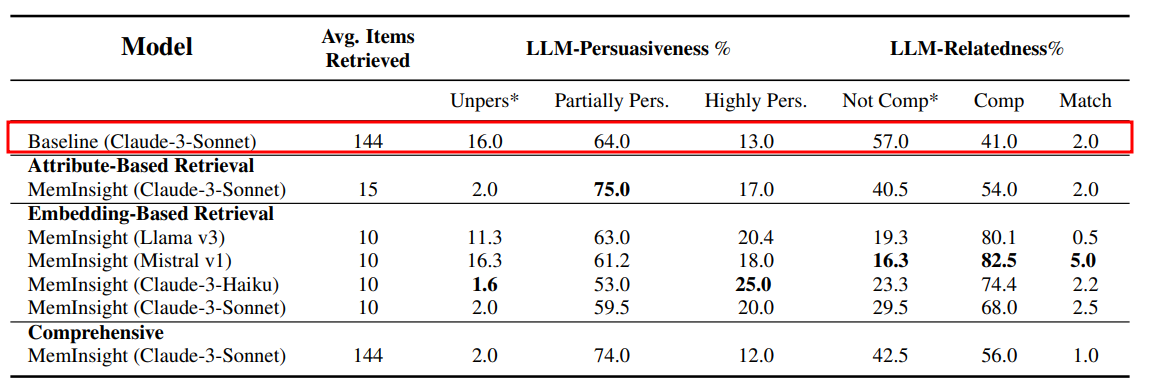
평가 항목 2가지
- 1. Persuasiveness (설득력)
- Unpersuasive : 설득력 전혀 없음, 낮을수록 좋음
- Partially Persuasive : 그럴듯한데, 뭔가 약함
- Highly Persuasive : 매우 설득력 있음
- 2. Relatedness (관련성)
- Not Comparable : 관련 없음, 낮을 수록 좋음
- Comparable : 비슷한 분위기 / 장르 / 주제
- Math : 거의 정답 수준으로 일치
결론 및 한계
세 가지 대표 작업에서 성능 입증
- 질문 응답: F1, Recall, 특히 Multi-hop reasoning에서 향상
- 영화 추천: 설득력, 관련성, 장르 일치도 모두 상승
- 이벤트 요약: Turn-level 속성 + 원문 결합이 가장 효과적
Priority 기반 속성 정렬이 성능 향상에 특히 효과적
- 검색 품질 및 문맥 파악력 상승
기존 RAG 방식의 한계를 보완
- 단순 retrieval이 아니라 의미 중심의 맞춤형 메모리 검색 가능
속성 생성의 품질 문제
- 속성 추출은 LLM을 통해 수행되므로, LLM의 환각(hallucination) 현상이 직접적인 영향을 줄 수 있음
- 잘못된 속성 추출 → 잘못된 기억 → 잘못된 응답
평가지표의 한계
- 일부 실험은 LLM 기반 평가라 객관적이지 않음
대규모 테스트 부족
- 실제로 논문에서 다룬 Task는 3가지
속성 정의의 유연성 부족
- 현재 사용된 속성들(예: 감정, 의도, 주제 등)은 사전에 정의된 스키마 사용
- 상황에 따라 속성 유형을 새롭게 만들어내는 능력은 아직 없음



