Bayesian Optimization(베이지안 최적화)
- 베이지안 최적화 방법 핵심은 사전 정보를 최적 값 탐색에 반영하는 것
사전 정보란?
- 사전에 검색/입력된 파라미터와 사전에 정의된 목적함수의 결과 셋
검색/입력된 파라미터 : 입력값 x
사전에 정의된 목적 함수 : 미지의 목적함수 f(x), black-box function
따라서 사전 정보는
- ( (x1, f(x1)) , (x2, f(x2))... (xn, f(xn)))
사전 정보를 생성한 후
- 위 같은 사전 정보를 바탕으로 Surrogate Model을 생성함
Surrogate Model
- 대리/대체 모델이라고도 불림
- 기존 입력 값을 바탕으로 미지 함수 f(x) 형태에 대한 확률적인 추정을 하는 모델
Surrogate Model이 미지 함수에 대한 확률적인 추정을 하는 모델인데, 어떻게 하이퍼 파라미터를 찾는가?
- Acuquistion function을 사용함
Acuquistion function
- 다음번에 탐색할 입력값 후보를 추천함
- Surrogate Model이 추정한 결과를 바탕으로 하는데, 추정 결괏값이 크면 최적 값일 가능성이 높다는 듯
- 최적 값이 높은 값은 다음번 탐색할 입력값 후보로 제공
베이지안 최적화 수행 과정(with 그림)
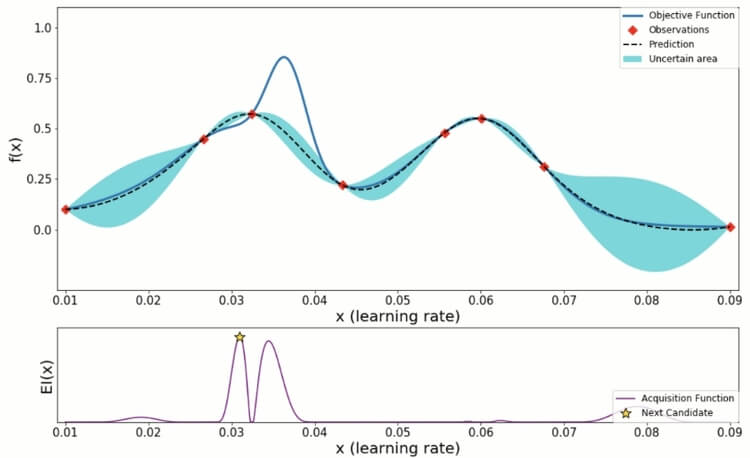
파란색 실선 : 미지의 목적 함수 f(x)
검은색 점선 : 사전 정보를 바탕으로 예측한 함수(estimated function)
파란색 영역 : 목적 함수 f(x)가 존재할 만한 신뢰 구간(function variance)
보라색 선 차트 : EI(x)는 Acuquistion function
베이지안 최적화 수행 과정에 필요한 입력값
- 하이퍼 파라미터(입력값 x)
- 미지의 목적함수 f(x)
- 입력값 x 탐색 구간 : (a, b)
- 관측할 입력값-함수 결괏값 개수 : N
- 입력값-함수 결과값 점들 개수 : n
과정
- 탐색 구간 (a, b) 내에서 입력 값 x를 random으로 n개 선택
- x1, x2, x3이 선택된 경우, 사전 정보 ((x1, f(x1)) , (x2, f(x2)), (x3, f(x3)))를 바탕으로 Surrogate Model 생성, 이 모델은 확률 추정이 가능함
- 탐색 구간(a, b) 내에서 EI값이 가장 큰 점을 다음 입력값 파라미터 후보로 지정(후보로 지정된 값은 x4라고 예를 들겠음)가EI가 가장큰 파라미터들로 모델을 학습 시키고, 입력값에 x4를 추가함.
즉, 지금 사전 정보는 ((x1, f(x1)) , (x2, f(x2)), (x3, f(x3)), (x4, f(x4)) - 다시 이 새로운 입력값을 가지는 사전 정보로 Surrogate Model을 업데이트함. 업데이트되면 당연히 확률적인 추정이 변화함
- 그러고 다시 탐색 구간 (a, b)내에서 EI 값이 가장 큰 점을 다음 하이퍼 파라미터 후보로 지정하며 이 과정을 사전에 정의한 N개가 될 때까지 반복함
- N개의 관측 중에서 최적의 해를 하이퍼 파라미터로 지정
'Study > ML 공부' 카테고리의 다른 글
| Few shot learning? Meta Learning? (1) | 2022.12.12 |
|---|---|
| [Study] SVD vs TruncatedSVD 차이점 (0) | 2022.05.21 |
| [Study] AdaBoosting vs GradientBoosting 차이점 (0) | 2022.04.17 |
| [Study] ExtraTreesClassifier vs RandomForestClassifier 차이점 (0) | 2022.04.03 |
| 원핫인코더 fit은 한번만 할 껀데? (feat.check_is_fitted, try-except , if - else) (0) | 2022.03.23 |



