사이킷런에서는 앙상블 모델인 AdaBoostingClassifier와 GradientBoostingClassifier를 지원합니다
본 포스팅은 둘의 차이점이 궁금해 공부하며 정리한 포스팅이며, 다른 훌륭한 분들의 블로그를 많이 참조했습니다.
Ensemble Model
앙상블 방식에는 Bagging, Boosting, Stacking 등이 있는데 그중 AdaBoosting과 GradientBoosting은 Boosting 방식입니다.
AdaBoostingClassifier vs GradientBoosting 차이점 한줄 요약
- AdaBoosting은 Stump로 구성되어 있고 하나의 Stump에서 발생한 Error가 다음 Stump에 영향을 주며 서로 순차적으로 계속 연결되어 최종 결과를 도출함
- 반면에 GradientBoost는 Stump가 아닌 Tree구조로 하나의 Leaf Node부터 시작함
AdaBoosting?? Stump?? Stump에서 발생한 Error??
설명을 돕기위해 AdaBoosting에 대해 정리합니다.
AdaBoosting
- 아이디어 : 후속 모델은 이전 모델의 오류를 수정해서 만들어짐, 점진적으로 개선되는 느낌은 gradient descent와 비슷함
- 이전의 약한 분류기(weak learner)에서 잘못 분류된 데이터에 큰 가중치를 주어 그 다음 약한 분류기를 학습할 때 반영시키는 것
- 최종 예측은 모든 약한 학습자(weak learner)의 예측 평균이며, 가중치가 높은 학습자는 최종 예측에 영향을 많이 미침
잘못 분류된 데이터에 큰 가중치를 준다고??
하나의 Stump가 잘못 분류한 sample에 대해서는 다음 Stump로 넘겨줄 때 가중치를 더 높여서 주는데 이는 다음 Stump가 해당 Sample에 더 집중해서 올바르게 분류해주기 때문이다.
- 각 샘플링 데이터가 5개 있다고 가정하고, 샘플 웨이트를 1/5로 하자
- 이중에 3번 샘플에 대해 틀렷다면, New Sample weight를 구해 다음 학습자에게 전해준다.
- 틀린 샘플 가중치는 올라가고, 맞은 샘플 가중치는 내려감, New Sample Weight를 구하는 공식은 따로 존재하며 , 가중치의 합은 1이 되어야 하기 때문에 계산 후 정규화를 해준다.

가중치를 이용해 다음 샘플 데이터를 만드는 방법은 아래와 같다
- 0 ~ 1에서 임의의 값을 하나 뽑는다
- 뽑힌 값이 0.1인 경우, 기존 데이터셋에서 첫 번째 데이터를 새로운 Dataset에 추가함
- 뽑힌 값이 0.1 ~ 0.3사이인 경우, 기존 데이터셋에서 두 번째 데이터를 새로운 Dataset에 추가함
- 뽑힌 값이 0.3 ~ 0.8 사이인 경우, 기존 데이터셋에서 세 번째 데이터를 새로운 Dataset에 추가함
이것이 잘못 분류된 데이터에 가중치를 높여서 잘못 분류한것에 집중할 수 있게 해주는 AdaBoosting의 데이터셋 생성 과정이다.
가중치가 높은 학습자가 결과에 영향을 더 많이 준다고?
설명하기전 알아야 할 것 : Decision Stump
- 하나의 노드에 두 개의 (leaf)를 지닌 트리를 decision stump라고 함
- AdaBoost는 여러 개의 decision stump로 구성되어 있고 이를 , Forest of decision stumps라고 부름
- decision stump가 곧 AdaBoosting에서의 약한 학습자(weak learner)가 됨
가중 치가 높은 학습자
가중치가 높은 학습자 말에서 왜 약한 학습자(weak learner)라는 말을 사용하지 않았냐면,
가중치가 높다 == 예측이 좀 더 정확하다인데, 이것을 약한 학습자(weak learner)라고 부르기는 애매하다.
따라서 학습자(Learner)라고 지칭했다.
- 마지막 decision stump는 이 전의 decision stump가 분류한 것을 계속 수정해 왔기 때문에 이전 분류기 보다 좀 더 정확한 경우가 있음
- 하지만 무조건 정확하다고 확신할 수 없기 떄문에 'Amount of say'를 구함
- 'Amount of Say'가 높으면 뭐가 좋냐면, 마지막 최종예측에서 'Amount Of Say'가 높을수록 결과에 영향을 많이 미침니다.
- 이것을 Amount of Say가 높은 Decision Stump라고 하며, 가중치가 높은 Decision Stump라고도 할 수 있음
- 최종 예측은 각 Decision Stump의 결과의 Amount of Say를 반영해 종합하여 최종 예측을 합니다.
GradientBoosting?? Leaf Node에서 시작하는 게 무슨 소리인가?
설명을 돕기위해 GradientBoosting에 대해 정리합니다.
GradientBoosting
Leaf Node에서 시작한다는 것은 쉽게 말해 특정 예측값에서 시작하는 것입니다.
예를 들어 설명하겠습니다.
- 하루에 마신 커피수, 프로젝트 수, 경력을 가지고 연봉을 예측해야 하는 분류기가 있다.
- 그렇다면 처음에 6개의 연봉의 평균값으로 예측하는 것이 일반적이라고 가정하겠다.
- 그러면 평균값이자 초기예측은 350이며, GradientBoosting이 Leaf Node에서 시작한다고 했으니 350에서 시작해보겠다.
GradientBoosting에서 자주 쓰는 개념은 Pseudo Residual이며, 이것은 그냥 '오차'라고 생각하자.
4. 초기 예측값과 각 데이터의 연봉에 대한 오차(residual)를 계산했다.
%%
Decision Tree가 어떤식으로 뻗어 나가는지 느낌을 알고 싶으면 아래 블로그를 참고하고, 자세히 알고 싶으면 다른 사람 블로그를 참고하자
https://junnyhi.tistory.com/114
[Study] ExtraTreesClassifier vs RandomForestClassifier 차이점
사이킷런에서는 Tree 기반 앙상블 모델인 ExtraTreesClassifier와 RandomForestClassifier를 제공합니다. 앙상블 모델 앙상블 방식에는 Bagging, Boosting, Stacking 등이 있는데 RandomForestClassifier는 Baggin..
junnyhi.tistory.com
5. 그 다음 이 오차값으로 Decision Tree를 생성할 것이다.
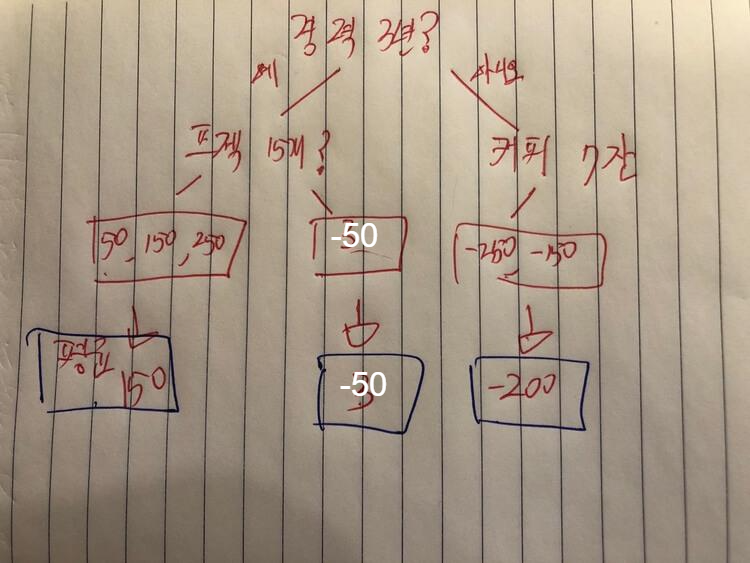
오차(Residual)를 예측하는 Tree를 생성하는 이유는 Learning rate를 사용하기 위함이다.
그림 2에서 Leaf Node에 여러 개의 값이 나오면 평균을 계산해, 평균으로 대체한다.
가운데 결과값이 '-50'인 데이터셋을 예로 들면,
- 초기 예측값 350에 , 오차값 '-50'을 더해서 원래 예측값을 업데이트할 것이다.
- 350 + -50 = 300이란 값이 나오며 이것은 원래 연봉값이랑 동일하다.
- 따라서 이것을 반복하는 것은 의미가 없고 이제 우리는 앞서말한 Learning rate를 사용할 것이다.
Learning rate의 default값은 0.1로 계산하겠다.
계속해서 업데이트 되는 예측값 = 이전 업데이트된 예측값 + Learning_rate * 업데이트되는 오차값
계산해보면, 350 + 0.1 x -50 = 345이다. 이 값은 처음 350으로 예측했을 때 보다 더 정확하다고 할 수 있지 않은가
따라서 이번 계산에서 업데이트되는 오차값은 300 - 345 = -45가 될 것이다.
이제 이 과정을 반복해서 원래값으로 찾아가는 것이 GradientBoosting의 작동원리이다.
부족한게 많은 글이며, 지적감사합니다.
'Study > ML 공부' 카테고리의 다른 글
| Bayesian Optimization(베이지안 최적화)란? (0) | 2022.08.14 |
|---|---|
| [Study] SVD vs TruncatedSVD 차이점 (0) | 2022.05.21 |
| [Study] ExtraTreesClassifier vs RandomForestClassifier 차이점 (0) | 2022.04.03 |
| 원핫인코더 fit은 한번만 할 껀데? (feat.check_is_fitted, try-except , if - else) (0) | 2022.03.23 |
| 워드 임베딩과 텍스트 벡터화 차이점 (0) | 2022.03.01 |



