사이킷런에서는 Tree 기반 앙상블 모델인 ExtraTreesClassifier와 RandomForestClassifier를 제공합니다.
앙상블 모델
앙상블 방식에는 Bagging, Boosting, Stacking 등이 있는데 RandomForestClassifier는 Bagging 방식입니다.
ExtraTreesClassifier vs RandomForestClassifier
첫 번째 차이점을 알기 전 알아야 할 지식
1. Bagging
- Bagging이란 Bootstrap aggregating의 줄임말입니다.
- Bootstrap은 중복을 허용한 랜덤 샘플링을 뜻합니다. 즉, 복원 추출로 생성된 샘플링 데이터셋입니다.
- aggregating의 뜻은 결합입니다.
- 따라서 Bagging 방식이란 중복을 허용해서 데이터셋을 랜덤 샘플링하여 각각의 트리를 학습하고, 각 트리의 결과를 aggregating(결합)하는 것입니다.
- RandomForestClassifier의 앙상블 방식입니다.

첫 번째 차이점, 복원 추출 여부
- RandomForestClassifier 경우 사진 1처럼 완전한 Bagging 방식입니다.
- 랜덤 포레스트를 구성하는 각 Decision Tree들이 복원 추출을 허용하는 랜덤 샘플링 데이터셋에 의해 학습이 됩니다.
하지만
- ExtraTreesClassifier는 복원 추출을 허용하지 않습니다. ExtraTresClassifier는 Bagging이라고 할 수 없습니다.

두 번째 차이점을 알기 전 알아야 할 지식
- 노드가 뻗어나가면서 트리를 만드는 방법입니다.
- 아래 그림들을 본적이 많을 거라고 예상합니다.
- 각 트리들은 노드들로 구성되어 있고 각 노드들은 또 다른 노드로 분할해 나갑니다.
- 노드들은 데이터셋 피쳐에 대한 특정 규칙에 의해 나눠지며, 마지막 leaf들이 가진 규칙은 서로 중복되지 않습니다.
leaf node?
자식 노드가 더 이상 없는 노드를 뜻함

특정 규칙에 의해 나눠진다? 규칙이 중복되지 않는다? 무슨 말인가
예를 들겠습니다.
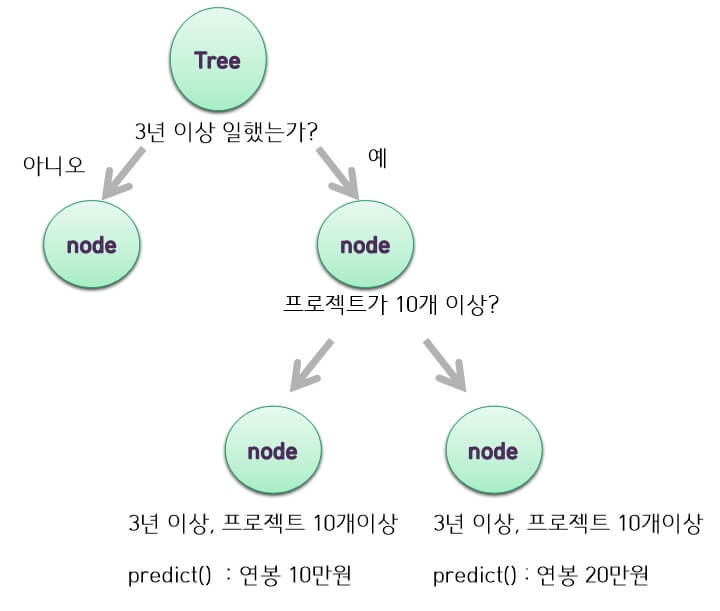
머신러닝 엔지니어의 연봉을 예측하는 RandomForestClassifier가 있습니다.
전체 데이터셋 중에 랜덤 샘플링을 통해 나온 데이터셋 A가 생성되었습니다.
A데이터셋은 근무시간, 진행한 프로젝트 수, 섭취한 총커피의 수와 같은 3가지의 피쳐를 가지고 있습니다.
예를 들어 첫 번째 노드에서 데이터셋 피쳐 '근무시간'에 대해 특정 규칙 '3년'을 적용시키면 아래와 같이 노드들이 뻗어나갑니다.

이런 식으로 뻗어나가면 그림 4처럼 마지막 leaf 노드들이 가진 규칙들은 서로 중복이 되지 않아서 분류를 할 수 있다는 것이 Tree기반 모델의 아이디어입니다.
위 그림에선 최상단 노드를 '근무시간'이라는 피쳐를 임의로 정했지만 최상단 노드를 선택하는 기준은 따로 있습니다.
그것은 정보 이득(information gain) 량을 계산해서 값이 가장 높은 피쳐를 선택합니다
정보 이득(Information gain)
부모 노드 엔트로피 - 자식 노드 엔트로피
Classifier 모델에서 정보 이득을 계산할 때는 엔트로피나 지니계수를 사용합니다.
포스팅에서는 엔트로피와 지니계수는 높을수록 안 좋다고 생각하시면 될 것 같습니다.
부모 노드 엔트로피 - 자식 노드 엔트로피? 말이 너무 어려워
그냥 주어진 피쳐에서 데이터셋을 잘 분류할 수 있는 피쳐가 정보 이득량이 가장 많다고 생각하시면 됩니다.
예를 들겠습니다.
'강아지' , '고양이', '참새' 데이터셋이 있습니다.
날개, 울음소리, 눈이라는 정보로 그들을 분류해 나가야 합니다.
제가 생각하기엔 일단 (강아지, 고양이) vs (참새)로 나누는 게 제일 좋은 것 같습니다.
그렇다면 '날개'라는 피쳐로 그들을 분할해야겠죠?? 그렇다면 '날개'가 가장 정보 이득량이 많은 것입니다.
두 번째 차이점, 최상단 노드 선택
최상단 노드는 정보 이득량이 가장 많은 노드가 선택되며 밑으로 분할(Split)한다고 설명드렸습니다.
그렇다면 RandomForestClassifier의 경우, 주어진 피쳐에 대해 모두 정보 이득량을 계산합니다.
예를 들어, 위 '강아지' , '고양이' , '참새' 데이터셋에서 날개, 울음소리, 눈이라는 피쳐를 가진 것을 기억할 것입니다.
그렇다면 RandomForestClassifier의 경우 최상단 노드를 선택하는 단계는 아래와 같습니다
- '날개' 피쳐가 최상단 노드로 선택되었을 때 정보 이득(부모 엔트로피 - 자식 엔트로피)을 계산
- '울음소리'가 최상단 노드로 선택되었을 때 정보 이득(부모 엔트로피 - 자식 엔트로피)을 계산
- '눈' 피쳐가 최상단 노드로 선택되었을때 정보 이득(부모 엔트로피 - 자식 엔트로피)를 계산
- 가장 정보 이득이 많은 피쳐를 최상위 노드로 선택
반면에 ExtraTreesClassifer의 경우, 주어진 피쳐에서 무작위로 피쳐를 하나 선택합니다.
말 그대로 ExtraTreesClassifier는 주어진 피쳐 중에서 무작위로 피쳐를 뽑아, 최적의 규칙(기준)을 정하고 분할해 갑니다.
최적의 규칙이란 '근무시간'이라는 피쳐가 무작위로 선택되었으면, 근무시간을 3년을 기준으로 분할했을 때 가장 좋은가, 2년을 기준으로 분할했을 때 가장 좋은가만 계산하고 분할해 갑니다.
이러한 특징 때문에 ExtraTreesClassifier가 계산법이 RandomForestClassifier보다 빠른 장점이 있습니다.
'Study > ML 공부' 카테고리의 다른 글
| Bayesian Optimization(베이지안 최적화)란? (0) | 2022.08.14 |
|---|---|
| [Study] SVD vs TruncatedSVD 차이점 (0) | 2022.05.21 |
| [Study] AdaBoosting vs GradientBoosting 차이점 (0) | 2022.04.17 |
| 원핫인코더 fit은 한번만 할 껀데? (feat.check_is_fitted, try-except , if - else) (0) | 2022.03.23 |
| 워드 임베딩과 텍스트 벡터화 차이점 (0) | 2022.03.01 |



