신입 자라기 107일 차, 월요일
하루 일과
| 시간 | 일과 |
| 8 : 00 | 기상 |
| 9 : 00 ~ 10 : 00 | 출근 시간 |
| 10 : 00 ~ 11 : 30 | 1. 솔루션 설치를 위한 쉘스크립트 작성 |
| 11 : 30 ~ 12 : 30 | 점심 시간 |
| 12 : 30 ~ 18 : 00 | 1. 솔루션 설치를 위한 쉘스크립트 작성 |
| 18 : 00 ~ 19 : 00 | 저녁 시간 |
| 19 : 00 ~ 20 : 30 | 1. 솔루션 설치를 위한 쉘스크립트 작성 |
| 20 : 30 ~ 22 : 30 | 퇴근 및 휴식 |
| 22 : 30 ~ 25 : 00 | 1. 블로그 포스팅 2. 프로그래머스 |
.profile vs .bashrc 차이점
- 로그인 시 → /etc/profile 실행 →/etc/profile.d 안에 모든 쉘 스크립트 실행 → ~/.profile 실행 → ~/bashrc 실행
- bashrc(bash run command) - bash 쉘을 통해 로그인 했을 경우
- 환경 설정은 profile, 함수 설정은 bashrc를 권장
for문을 사용한 array에 값 추가하는 방법 - 쉘스크립트(== list.append())
var=(a, b, c)
arr=()
for v in $[var[@]]
do
arr+=($v)
done
echo $[arr[@]]
a b c출근길에 보는 머신러닝 실천 이론
편향과 분산의 트레이드오프(Bias-variance tradeoff)
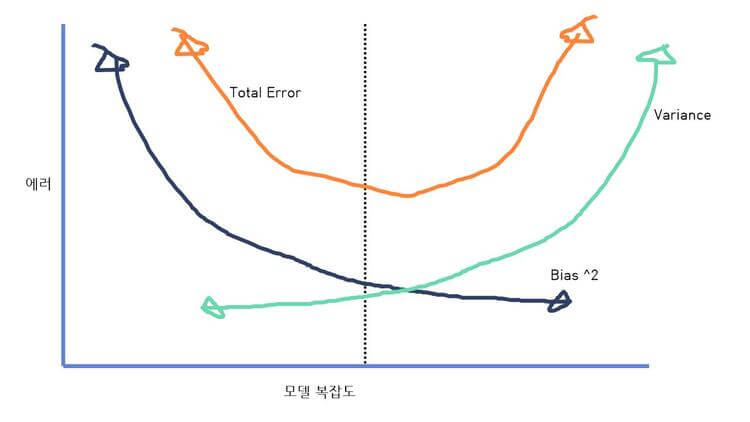
- 모델이 복잡해진다 -> 편향(Bias)는 작아진다 -> 분산(Variance)은 커진다. -> 과적합(over-fitting)
- 모델이 단순해진다 -> 편향(Bias)는 커진다 -> 분산(Variance)은 작아진다 -> 과소 적합(under-fitting)
결론 : 둘 다 적당히 낮은 합의점 구간을 찾기
편향(Bias)
- 높다 -> 실제 값과 예측값의 오차가 크다(실제값과 예측값의 차이)
분산(Variance)
- 높다 -> 과하게 복잡한 모델로 인한 에러 -> 이상한 것(Noisy) 같은 것도 모두 학습해 입력값에 대한 예측값 분포가 넓음
RNN 구현하기
RNN에서 변하지 않는 값들
- W_x(입력층을 위한 가중치값
- W_y(출력층을 위한 가중치값)
- W_h(은닉 상태 값을 위한 가중치값)

import numpy as np
# 입력 시퀀스 길이(== input_length)
timesteps = 10
# 입력 크기(차원)
input_dim =4
# 메모리 셀 용량
hidden_units = 8
# 입력 텐서 생성
# np.random.random((길이, 차원)) -> 튜플로 넣어야함
inputs = np.random.random((timesteps, input_dim))
print(inputs)
초기 은닉상태 -> 0
# 초기 은닉 상태는 0(벡터)로 초기화
# np.zeros() ->0으로 채워진 array 생성
hidden_state_t = np.zeros((hidden_units,))
print(hidden_state_t)
print(hidden_state_t.shape)
# Docstring:
# zeros(shape, dtype=float, order='C', *, like=None)
print(np.zeros((hidden_units)) )
각각의 가중치 정의
# 가중치 정의
# 각 가중치의 차원은 입력과의 행렬 곱셉때문에 차원을 맞추는것
# 입력에 대한 가중치 - W_x, (8, 4)크기의 2D 텐서
Wx = np.random.random((hidden_units, input_dim))
# 은닉상태(Hidden State)에 대한 가중치 W_h - (8, 8) 크기 텐서
Wh = np.random.random((hidden_units, hidden_units))
# bias
b = np.random.random((hidden_units,))RNN(recurrent neural network) 이름 처럼 단순 순환 방식으로 은닉 상태(hidden state) 업데이트
for input_ in inputs:
# Wx * Xt + Wh * Ht-1 + b(bias)
# np.dot -> 행렬 곱셈
output_t = np.tanh(np.dot(Wx,input_) + np.dot(Wh,hidden_state_t) + b)
hidden_state_t = output_t
print(output_t)
'Study > 신입 자라기' 카테고리의 다른 글
| [Study] 신입 자라기 - 109 (0) | 2022.07.21 |
|---|---|
| [Study] 신입 자라기 - 108 (0) | 2022.07.20 |
| [Study] 신입 자라기 - 106 (0) | 2022.07.16 |
| [Study] 신입 자라기 - 105 (0) | 2022.07.15 |
| [Study] 신입 자라기 - 104 (0) | 2022.07.14 |



