Sequence to Sequence Learning with Neural Networks
원문 : https://arxiv.org/abs/1409.3215
Sequence to Sequence Learning with Neural Networks
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this pap
arxiv.org
개요
이번 포스팅에서는 Sequence to Sequence Learning with Neural Networks 논문을 공부합니다
나는 사용했다 구글 번역기 번역을 위해서
참고 자료
1. 동빈나님의 꼼꼼한 딥러닝 논문 리뷰, https://www.youtube.com/watch?v=4DzKM0vgG1Y&t=1954s
2. 조원호님의 Notion 문서 : https://www.notion.so/wonhocho/Sequence-to-Sequence-Learning-with-Neural-Networks-d221d4ed2e9241e29047d95a6a9e00b2
들어가기 전
BLEU(Bilingual Evaluation Understudy) Score
- 기계 번역의 성능이 얼마나 뛰어난가를 측정하기 위해 사용되는 대표적인 방법
SMT(Statistical Machine Translation)
- 통계적 기계 번역
- 기계 번역 패러다임의 하나로서, 파라미터들이 2개 언어 말뭉치의 분석에서 비롯된 통계 모델에 기초한 번역 방법
Seqence( = 문장)
- 하나의 문장은 여러 개의 단어로 이루어짐
- 각각의 단어를 일반적으로 토큰으로 처리함(단어를 토큰이라고 표현하는 경우도 있음)
- 결국 여러 토큰이 모인 것이 하나의 Sequence
Long-Term Dependency
- 장기 의존성(문맥 의존성)
- 예시)
- 문장 : "그는 어제 회사 직원들과 다 같이 카페에서 야근했다 "
- 핵심 : "그는", "야근했다"
- 결론 : "그는", "야근했다" 사이에는 "어제", "회사 직원들과", "다 같이", "카페에서"라는 단어들이 존재해서 핵심 단어가 멀리 떨어져 있음. 이러한 경우 장기 의존성이 존재한다고 표현
Beam Search 방식
- Greedy 하게 확률이 높은 것만 선택하는 것이 아닌, 특정 깊이(Beam size) 만큼 들어가서 가장 큰 확률을 계속 찾는 것
- 결과적으로 출력 문장 중 확률이 가장 높은 것을 찾음
SGD(Stochastic Gradient Descent, 확률적 경사 하강법)
- 전체 데이터(Batch)가 아닌 무작위로 선택한 샘플 데이터(minibatch)를 사용하는 방법
Title : Sequence to Sequence Learning with Neural Networks
Abstract
- 인코더, 디코더는 LSTM을 이용해 구현하며, LSTM을 4번 쌓아 올려서 사용하며(LSTM Layer가 4개 층), "이것을 LSTM의 Multi layer구조다"라고도 말할 수 있음
- 영어를 불어로 번역하는 작업에 대해 BLEU 점수가 34.8점이 나왔는데, 이것은 Seq2 Seq가 나오기 전 방식인 SMT의 33.3에 비해 높게 나왔음
- 나아가 딥러닝 방식 + SMT 방식을 조합해, SMT 방식에서 나온 1000개의 hypothesis를 LSTM을 이용해 재 랭킹 하는 기법을 사용하니 BLEU스코어가 36.5점 까지 나왔음
- 추가적으로 LSTM을 이용해 Seq2Seq 모델을 사용하는 것뿐만 아니라, 학습 진행 중에 입력 문장에 포함된 단어 순서를 바꾸니 더 좋은 성능이 나왔음
1. Introduction
- 딥러닝 기법은 경사 하강법을 이용해 역전파를 통해 학습을 하게 되면, 복잡한 함수도 잘 학습을 할 수 있음, 만약 정해진 작업에 대해 적절한 함수의 파라미터가 존재한다면 충분히 경사 하강법을 사용해 높은 성능을 낼 수 있는 것이 증명되었고 현재는 딥러닝 기법이 다양한 작업에서 성공적인 성능을 보여주고 있음
- 뉴럴 네트워크는 전통적인 통계적 모델과 비교했을 때, 많은 유사성을 가지지만 더욱 복잡한 함수를 수행하는데 좋은 성능을 보임
- DNN기법은 강력하지만, 입출력 차원이 고정되는 경우가 많음(지금은 아님). 그래서 단어가 연속적으로 나오는 문장 (Sequence)를 처리하는 것은 어렵지만 LSTM을 이용해 Seq2 Seq문제를 해결할 수 있음
- LSTM구조의 Encoder을 통해서 입력 데이터에 대해, 큰 크기의 고정된 차원의 context vector를 추출하고, 또 다른 LSTM구조의 Decoder가 이러한 context vector를 입력으로 받아서 출력 Sequence를 뽑아냄(고정된 차원의 벡터는 매우 긴 문장에서 성능 하락의 원인이 되기 때문에 나중에 "Attention" 방식이 등장함)
- 4층의 LSTM구조는 Long Dependencies를 잘 해결할 수 있음
2. Model

위 수식은 예측에 관한 수식임.
좌변
- x1, x2...xT는 입력을 의미하며 입력 문장 X가 토큰 x1부터 xt까지 t개의 토큰으로 이루어짐을 의미
- y1,y2...yT'는 출력을 의미하며 T와 T'는 다를 수 있음.(이것은 입력 문장의 단어 개수가 출력문장의 단어 개수와 같을 필요가 없다는 것을 의미함)
우변
- 입력 문장은 하나의 context 문장 'v' 로 바뀌게 되며, 'v' 를 이용해 매번 출력 결과를 재귀적으로 Decoder를 통해 출력 문장을 만듦(이것은 Encoder에서 최종적으로 만들어낸 고정된 크기의 context vector인 'v'와 y1, y2..,yt-1까지의 input값이 주어지면 yt일 확률을 모두 곱해서 확률이 가장 높은 yt가 출력 문장이 되는 것)
- 이것을 p(yt|v,y1, ... yt-1))은 vocabulary 내의 모든 단어에 softmax를 적용한 것이라고 표현함

- EOS(End of Sequence)만 있다고 가정할 때, 입력은 A, B, C, EOS 순서로 들어갈 수 있고, Decoder는 W, X, Y, Z, EOS가 들어가는 방식
- Encoder와 Decoder파트에 사용되는 LSTM는 서로 다른 파라미터를 사용하며, 앞서 말했듯이 4개의 LSTM 사용
- 입력 문장의 단어 순서를 바꾸는 것이 성능 향상에 도움이 되었음, A, B, C -> C, B, A
- 즉, Input Sentence와 마지막에 문장의 끝을 나타내는 EOS 토큰을 Encoder에 넣어주면 고정 크기의 Context Vector를 만들어내고 이것을 다시 Decoder에 넣어 EOS토큰이 나올 때까지 번역 작업을 하게 됨
3.1 Dataset Details(데이터셋에 대한 세부사항들)
- 두 언어(불어, 영어)에 대해 고정된 크기의 단어 사전을 사용하며, 각각의 토큰을 하나의 단어로 보기 때문에, 각각의 단어를 특정 차원의 벡터로 표현할 수 있음.
- 총 단어 중 16만 개만 사용한다고 하면, 입력으로 들어오는 단어는 이 16만 개 단어에서 표현
3.2 Decoding and Rescoring
S : Source Sentence(Input Sentence)
T : Target Sentence(Sequence Prediction)
Training Objective를 수식으로 표현한 수식
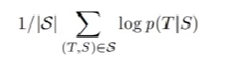
학습할 때
- 어떤 S가 들어오면, S에 매칭 되는 T가 나올 수 있게 학습을 진행
- Log를 취해서 확률 값 극대화

테스트할 때
- 학습 완료 후, 가장 높은 확률을 가지는 T를 리턴(위 식을 통해 번역 결과를 생성하는데 번역 과정에는 Left-to-Right Beam Search Decoder를 사용)
3.4 Training Details
학습을 위한 세부 기술들
- LSTM 4 중첩
- 워드 임베딩을 총 1000차원으로 만듦
- 사전에 포함된 단어의 개수가 많기 때문에 먼저 1000차원의 워드로 임베딩 되게 했으며, LSTM에 사용되는 Cell의 크기는 총 100개
- LSTM에 포함되어 있는 파라미터 값 들은 -0.08 ~ 0.08 사이 값으로 Uniform 분포를 따름
- Momentum 없이 SGD(Stochastic Gradient Descent)를 이용해 학습을 진행하며, 학습 진행 동안 Learning rate를 줄여나감
- Batch size는 128
- 단순히 랜덤 하게 문장을 구성해서 128개만큼 하나의 Batch를 구성하면, 문장 길이가 차이가 많이 나는 경우는 Padding을 채워야 하는데, 여기서 많은 낭비가 발생할 수 있음. 따라서 minibatch안에 포함되어 있는 각각의 문장들이 최대한 비슷한 길이가 되도록 해서 학습 속도를 줄임
5. 결론
- LSTM을 깊게 쌓아서(4 중첩) 기존 SMT와 비교하면 더 좋은 성능을 냄
- 입력 단어 순서를 바꾸는 방법이 성능 개선에 많은 도움을 줌
- LSTM을 이용해서 Encoder를 거쳐서 하나의 고정 크기의 context vector를 만들고, 이 벡터를 LSTM 기반의 Decoder를 거쳐서 번역 결과를 만들어냄
'논문' 카테고리의 다른 글
| [논문 공부] Transformer : Attention IS All YOU NEED (0) | 2022.07.25 |
|---|---|
| [논문 공부] LSTM(Long Short-Term Memory)(feat. RNN) (0) | 2022.07.16 |
| [모델공부]U-Net : Image segmentations (0) | 2022.01.10 |
| [모델구현]Unet 네트워크 구현하기(with Pytorch) (1) | 2022.01.09 |
| [논문 공부]SSD : Singl1e Shot Multibox Detector (0) | 2021.12.25 |



