사이킷런 개발 버전 도큐먼트입니다.
https://scikit-learn.org/dev/whats_new/v1.1.html
Version 1.1.0
In Development Legend for changelogs:: something big that you couldn’t do before.,: something that you couldn’t do before.,: an existing feature now may not require as much computation or memory.,:...
scikit-learn.org
아직 안정화되지 않은 버전이며, 사용 가능한 공식 버전은 1.0입니다.
업데이트 내용
1. warm start

RamdomForestClassifier와 ExtraTreesClassifier알고리즘은 멀티 프로세싱을 통해 더 빨리 학습할 수 있고, warm_start 옵션을 사용하면 더욱 좋은 효과가 있음
warm start란?
이미 한번 이상 실행한 뒤로 데이터가 메모리에 일부 캐시 된 상태로 시작하는 것
사이킷런이 fit() 메서드가 호출될 떄 기존 트리를 유지하고 훈련을 추가할 수 있도록 함
2. criterion = 'log_loss'

RandomForestClassifier와 ExtraTreesClassifier는 criterion옵션으로 'gini'와 'entropy' 말고도 'log_loss'를 사용할 수 있습니다.
2.1 log_loss란?
- 모델이 예측한 클래스에 대해 확신하는 확률을 가지고 분류 모델의 평가 지표 중 하나이며, 0에 가까울수록 정확
- 사이킷런에서는 predict_proba를 사용하면 이 확률을 확인할 수 있음
극단적인 예를 들어서 설명하면,
연봉 1억 인 5년 차 개발자가 있습니다.
그리고 A, B에게 5년차 개발자 연봉을 맞춰보라고 질문합니다.
A : 5년차 개발자면, 연봉 1억이라고 99%라고 확신해!
B : 5년차 개발자면, 연봉 1억이라고 30%라고 확신해!
라고 답변했을 경우 A가 정답에 더 정확하다고 반영하는 것입니다.
이를 확률 값을 사용하기 위해 'log_loss'에서는 '-log(x)' 값을 사용합니다.
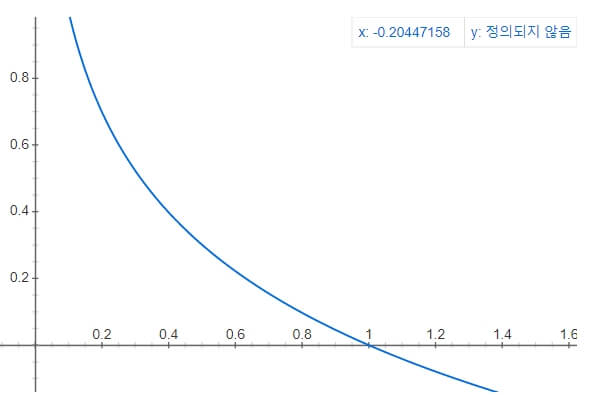
모델이 예측한 클래스에 대해 확신하는 확률이 100% 인 경우
log_loss 값은 -log(1.0)이며, 0입니다.

하지만 모델이 예측한 클래스에 대해 확신하는 확률이 30% 인 경우
log_loss 값은 -log(0.3)이며, 0.52입니다.

따라서 확신하는 확률이 낮을수록 logloss값은 증가하게 됩니다.
결론적으로 모델은 log_loss값이 낮아지는 방향(확신 확률 100%)으로 학습하는 것입니다.
'Study > 신입 자라기' 카테고리의 다른 글
| [Study] 신입 자라기 - 54 (0) | 2022.04.27 |
|---|---|
| [Study] 신입 자라기 - 53 (0) | 2022.04.26 |
| [Study] 신입 자라기 - 52 (0) | 2022.04.22 |
| [Study] 신입 자라기 - 51 (0) | 2022.04.22 |
| [Study] 신입 자라기 - 50 (0) | 2022.04.21 |



