하지만 아래 PyPDFDirectoryLoader처럼, load를 오버라이드할 때는 메타데이터 값이 다를 수 있음
classPyPDFDirectoryLoader(BaseLoader):"""Load a directory with `PDF` files using `pypdf` and chunks at character level.
Loader also stores page numbers in metadata. """
[docs]
defload(self) -> list[Document]:
p = Path(self.path)
docs = []
items = p.rglob(self.glob) if self.recursive else p.glob(self.glob)
for i in items:
if i.is_file():
if self._is_visible(i.relative_to(p)) or self.load_hidden:
try:
loader = PyPDFLoader(str(i), extract_images=self.extract_images)
sub_docs = loader.load()
for doc in sub_docs:
doc.metadata["source"] = str(i)
docs.extend(sub_docs)
except Exception as e:
if self.silent_errors:
logger.warning(e)
else:
raise e
return docs
결론은 사용하고자 하는 로더가 필요한 메타데이터를 리턴 값으로 주는지 고려하자
아래 영상에서는 테디 님이 추천하신 몇 가지 로더와 특징들을 확인할 수 있다.
출처 : 테디노트 유튜브
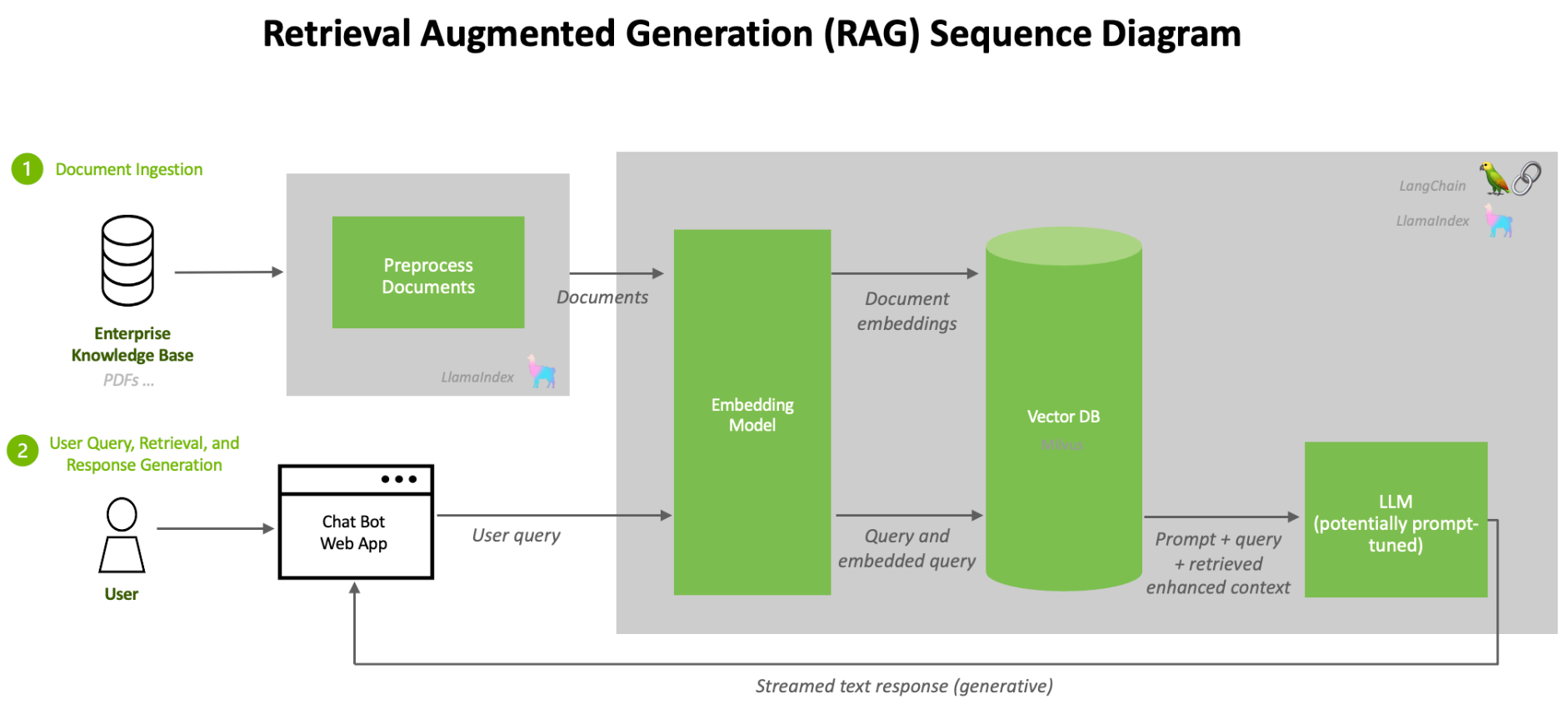
1.2. Split : 로드된 텍스트를 더 작은 청크(문단)로 분할하는 단계
왜 문서를 분할할까?
출처 : langchain docs
위 내용을 결국 요약을 하면
LLM 입력 토큰 제한이 있기 때문에
정확도를 향상하기 위해
LLM이 참고할 문서를 더욱 명확하게 하기 위해 -> 정확도 향상의 목적(2번)과 동일
비용을 절감하기 위해
Text splitters
그렇다면 어떤 텍스트 분할기를 써야 할까? 가 다음 문제이다
Langchain에서는 다양한 문서 로더뿐만 아니라 다양한 스플리터들도 지원하기 때문이다.
출처 : Langchain
각 분할 기법은 고유한 특징을 가지므로,
본인의 데이터 특성에 적합한 기법을 선택하는 것이 중요하다. 주요 분할 기법은 아래와 같다
문자 기반 분할 (Character-Based Splitting)
설정한 문자 수 기준으로 단순히 분할.
재귀적 문자 분할 (Recursive Character Splitting)
점진적으로 더 작은 구분자(\n\n, \n, , "")를 사용해 계층적으로 분할.
의미 기반 분할 (Semantic Splitting)
임베딩을 활용하여 의미에 따라 분할, 관련 있는 내용끼리 묶음.
정규식 기반 분할 (Regex-Based Splitting)
날짜나 특정 키워드와 같은 패턴을 기준으로 분할.
LLM 기반 분할 (LLM-Based)
AI 모델에 프롬프트를 제공해 콘텐츠 흐름에 따라 동적으로 분할 지점 결정.
출처: Rodrigo Nader, Medium
가장 범용적으로 사용되는 것이 "RecursiveCharacterTextSplitter"라고 함
본격적으로 시작하기 전에 "Runnable interface"를 이해할 필요가 있을 것 같음
나는 RAG를 공부할 때 코드 예제부터 봤는데, 속으로 생각했음
"튜플 자료형에 invoke..? 저게 뭐시여"
"LangChain Expression Language (LCEL)"을 알면 의문점이 풀린다
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
chain.invoke(
"Who is the main character in `Tokyo Ghoul` and does he transform into a ghoul?"
)
LangChain Expression Language (LCEL)
langchain Docs에서는 LCEL을 "Langchain 컴포넌트를 체인(연결)하는 선언적(declarative) 방법 "이라고 말하고 있음
내 이해를 정리해 보자면
- "Runnable"은 LangChain에서 데이터를 입력받고, 처리하고, 결과를 반환하는 단위
- "Chain" 은여러 단계를 연결한 실행가능한 작업 흐름
- 결론은 "Chain"은 단순히 데이터 흐름만 표현하는 게 아니라 결과를 반환할 수 있는 실행 가능한 단일 객체로 취급
LCEL 장점
특히, LangSmith로 결괏값들을 편리하게 확인할 수 있는 점이 엄청 편리해 보임
3가지 가이드라인
단일 액션을 할 때는 굳이 사용할 필요 없음
간단한 체인에 적합
엄청 복잡한 체인 만들 거면 LangGraph 사용하셈
AI Agent 같은 서비스를 만들 때 LangGraph, CrewAI, AG를 사용하는 것 같던데 뒤에서 알아보자
# 가상의 러너블 함수들defrunnable1(question):returnf"Answer from runnable1 for '{question}'"defrunnable2(question):returnf"Documents related to '{question}'"defrunnable3(answer, documents):returnf"Final answer: {answer} with supporting documents: {documents}"# 병렬 실행을 위한 매핑
mapping = {
"answer": runnable1,
"documents": runnable2
}
chain = mapping | runnable3
2.2 체인 만들기
Runnable interface에 대해 알아봤으니 이번에는 Chain을 먼저 만들어보자
아래 검색 및 생성 단계가 하나의 체인이 될 것이다
RunnablePassthrough() - RunnablePassthrough 클래스는 invoke() 메서드를 통해 입력된 값을 그대로 반환함
순서
사용자의 입력(question)을 invoke 메서드를 사용해서 체인에 전달
Runnable 한 특성을 가진 딕셔너리기 때문에 사실 "RunnableParallel"
question 값은 <1.4 벡터스토어> 단계에서 만들어 논 "retriever" 객체로 전달되어서 사용자 질문과 유사한 문서를 벡터 스토어에서 찾아서 결과를 반환함
RunaablePassthrough()가 question을 그대로 반환해 밸류값을 완성시킴
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"""
Answer the question based only on the context provided.
Context: {context}
Question: {question}
"""
)
langchain 프롬프트 허브도 있음
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
이 외에도 좋은 프롬프트가 많아서, 필요시 Pull 해서 사용하면 됨
2.4 LLM : 언어모델 생성하기
Langchain을 통해 사용가능한 모델들은 많으며, 역시나 선택의 문제이다
import getpass
import os
ifnot os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")