왜 웹 브라우저 자동화 도구(Selenium, Pupeteer)는 로그인 상태가 유지되지 않는가?
때는 타오바오 중국 쇼핑몰 파싱 하던 도중,
타오바오 특징이 로그인을 안 하면 쇼핑 검색을 할 수가 없어서 로그인 부터 자동화를 시도했다.
로그인 과정에서 슬라이딩 캡차?가 존재하는데, 흠..

헛짓거리의 흔적..
// 슬라이더 요소의 위치와 크기를 얻습니다.
const sliderElement = await page.$('selector');
const sliderBox = await sliderElement.boundingBox();
...
// 슬라이더의 시작점으로 마우스를 이동합니다.
const sliderStartX = sliderBox.x + sliderBox.width / 2;
const sliderStartY = sliderBox.y + sliderBox.height / 2;
await page.mouse.move(sliderStartX, sliderStartY);
...
await page.mouse.down();
await page.mouse.move(sliderStartX + 100, sliderStartY, { steps: 30 });
await page.mouse.up();
...
그러다가 그냥 꼼수로 다른 세션에서 로그인해두면 될까?
했지만 역시 안됐다.
그래서 왜 웹브라우저 자동화 도구는 세션 정보를 공유하지 않을까?
가 궁금해서 포스팅을 작성하기로 했다.
일반적으로 크롬 같은 브라우저는 쿠기와 세션을 공유하고 있기 때문에 다른 탭을 열어도 로그인 상태가 유지된다.

하지만 자동화 도구로 열린 브라우저는 비로그인 상태이다

왜 로그인 상태가 아닌가?
Selenium과 Puppeteer는 웹 브라우저를 자동화하기 위한 도구로, 각 인스턴스가 독립적인 환경을 가지기 때문임
실행환경이 독립적이기 때문에 쿠기와 세션정보가 공유되지 않았고 로그인 상태가 유지가 안된 것이다.
그래서 아래와 같이 크롬의 1번 탭과 2번 탭은 동일한 쿠기 정보를 가지고 있지만,

Selenium/Pupeteer로 실행한 브라우저는 독립적인 값들을 가지는 것을 확인할 수 있다

독립적인 실행환경을 가지는 이유가 뭘까?
가장 큰 이유는 웹 자동화도구의 목적성에 있다
웹 자동화 도구는 웹 애플리케이션 테스트에 많이 사용하기 때문에 여러 테스트 케이스를 독립 실행 및 결과 분리가 필요
- 이런 독립적인 환경은 테스트가 서로 영향을 주지 않기 때문에 정확한 결과 얻음
- 오류 발생해도 다른 인스턴스한테 영향을 주지 않고 인스턴스의 작업마다 프로식, 헤더 같은 사용자 설정도 가능
쿠키 정보 공유해서 해결?
로그인된 웹사이트의 쿠기 정보 추출 -> 인스턴스 실행 시 쿠기 정보 삽입인데 쿠키는 유효기간이 있어서 별 의미가 없음
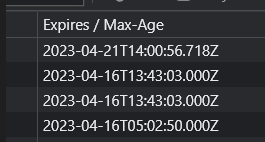
Expires
- 쿠기가 만료되는 날짜와 시간
Max-Age
- 쿠기가 만료되기까지 남은 시간
마무리
대형 프로그램들이 타오바오에서 데이터 파싱하는데 공통점을 발견했고 해당 방식으로 해볼 예정이다
'알쓸코잡' 카테고리의 다른 글
| dict.fromkeys()에 관한 사실 (0) | 2023.05.26 |
|---|---|
| 꼬리에 꼬리를 무는 Proxy 이야기 (0) | 2023.05.08 |
| [강좌] 개발자를 위한 ChatGPT 프롬프트 엔지니어링 - Andrew Ng (2) | 2023.04.29 |
| 꼬리에 꼬리를 무는 웹 스크래핑/크롤링 이야기 (0) | 2023.04.27 |
| 전혀 모르고 있다가 파이썬 3.12가 나왔다길래 읽어봤다는 내용 (0) | 2023.04.21 |



